正文
AphaGo
的原理,
Nature
上刊登的文章也缺乏一张刨解全局的图(加之用英文描述,同学们很难理解透彻)。以下是我跟微软亚洲研究院的张钧波博士在多次阅读原文并收集了大量其他资料后,一起完成的一张图,解释了
AlphaGo
的原理,看完后大家自然知道其弱点在何处了。
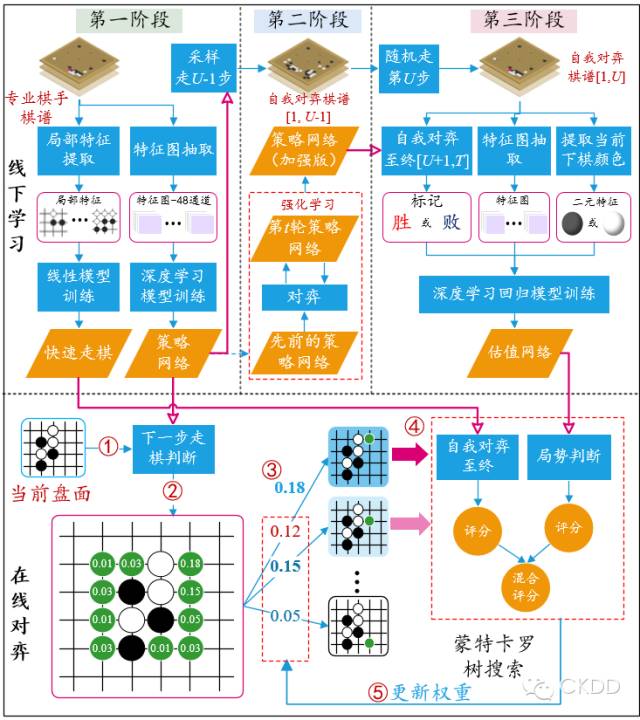
图1、AlphaGo的原理图 (作者为本图花费大量心血,版权归两位作者所有,欢迎转发,但请勿盗图)
AlphaGo总体上包含离线学习(图1上半部分)和在线对弈(图1下半部分)两个过程。
离线学习过程分为三个训练阶段。
-
第一阶段:
利用
3万多幅专业棋手对局的棋谱来训练两个网络。一个是基于全局特征和深度卷积网络(
CNN)训练出来的策略网络(Policy Network)。其主要作用是给定当前盘面状态作为输入,输出下一步棋在棋盘其它空地上的落子概率。另一个是利用局部特征和线性模型训练出来的快速走棋策略(Rollout Policy)。策略网络速度较慢,但精度较高;快速走棋策略反之。
-
第二阶段:
利用第
t轮的策略网络与先前训练好的策略网络互相对弈,利用增强式学习来修正第t轮的策略网络的参数,最终得到增强的策略网络。这部分被很多“砖”家极大的鼓吹,但实际上应该存在理论上的瓶颈(提升能力有限)。这就好比2个6岁的小孩不断对弈,其水平就会达到职业9段?
-
第三阶段:
先利用
普通的策略网络
来生成棋局的前U-1步(U是一个属于[1, 450]的随机变量),然后利用随机采样来决定第U步的位置(这是为了增加棋的多样性,防止过拟合)。随后,利用
增强的策略网