正文
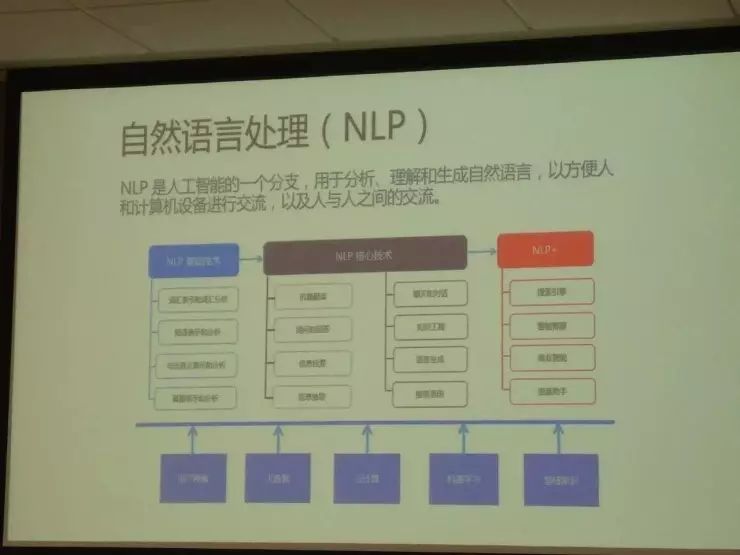
我介绍一下语言在认知智能的作用,在整个人工智能体系下的作用。自然语言处理就是体现语言智能重要的技术,它是人工智能一个重要的分支,帮助分析、理解或者生成自然语言,实现人与机器的自然交流,同时也帮助人与人之间的交流。我认为自然语言处理包括以下几方面内容,第一是 NLP 的基础技术,围绕不同层次的自然语言处理,比如说分词、词性标注、语义分析做一些加工。后面做任何其他新的技术或者应用都必须要用到基础技术。
中间这块是 NLP 核心技术,包括词汇、短语、句子、篇章的表示,大家所说的 Word Embedding 就是在研究不同的语言单位的表示方法。它也包括机器翻译、提问和回答、信息检索、信息抽取、聊天和对话、知识工程、语言生成、推荐系统。
最后是 “NLP+”,仿照 “人工智能 +” 或 “互联网 +” 的概念,实际上就是把自然语言处理技术深入到各个应用系统和垂直领域中。比较有名的是搜索引擎、智能客服、商业智能和语音助手,还有更多在垂直领域——法律、医疗、教育等各个方面的应用。
正如其他人工智能学科,自然语言处理也要有很多支撑技术、数据,包括用户画像,以提供个性化的服务,包括用来做训练之用的大数据,包括云计算提供、实施、训练的基础设施,包括机器学习和深度学习提供训练的技能。它一定要有各种知识支撑,比如领域知识还有常识知识。
微软对神经网络机器翻译的思考

这张图概括了神经网络机器翻译,简要的说,就是对源语言的句子进行编码,一般都是用的长短时记忆 LSTM,方向进行编码。编码的结果就是有很多隐节点,每个隐节点代表从句首到当前词汇为止,与句子的语义信息。基于这些隐节点,通过一个注意力的模型来体现不同隐节点对于翻译目标词的作用。通过这样的一个模式对目标语言可以逐词进行生成,直到生成句尾。中间在某一阶段可能会有多个翻译,我们会保留最佳的翻译,从左到右持续。

这里最重要的技术是对于源语言的编码,还有体现不同词汇翻译的,不同作用的注意力模型。我们又持续做了一些工作,引入了语言知识。因为在编码的时候是仅把源语言和目标语言看成字符串,没有体会内在的词汇和词汇之间的修饰关系。我们把句法知识引入到神经网络编码、解码之中,这是传统的长短时记忆 LSTM,这是模型,我们引入了句法,得到了更佳的翻译,这使大家看到的指标有了很大程度的提升。
此外,我们还考虑到在很多领域是有知识图谱的,我们想把知识图谱纳入到传统的神经网络机器翻译当中,来规划语言理解的过程。我们的一个假设就是虽然大家的语言可能不一样,但是体现在知识图谱的领域上可能是一致的,就用知识图谱增强编码、解码。具体来讲,就是对于输入句子,先映射到知识图谱,然后再基于知识图谱增强解码过程,使得译文得到进一步改善。
聊天机器人是下一个平台?
下一个方向就是 “对话即平台”,英文叫做 “Conversation as a Platform (CaaP)”。2016 年,微软首席执行官萨提亚在大会上提出了 CaaP 这个概念,他认为继有图形界面的下一代就是对话,它会对整个人工智能、计算机设备带来一场新的革命。
为什么要提到这个概念呢?我个人认为,有两个原因。
第一个原因,源于大家都已经习惯用社交手段,如微信、Facebook 与他人聊天的过程。我们希望将这种通过自然的语言交流的过程呈现在当今的人机交互中,而语音交流的背后就是对话平台。第二个原因则在于,现在大家面对的设备有的屏幕很小,有的甚至没有屏幕,所以通过语音的交互,更为自然直观的。因此,我们是需要对话式的自然语言交流的,通过语音助手来帮忙完成。










