正文


我们从两幅视频截图中可以看出,每位歌唱者面前都摆放了独立的麦克风,这种麦克风从外观来看动圈式的可能性更大,
动圈式麦克风的灵敏度要低于电容麦克风,其可拾取的声音频段也不如电容麦克风。
动圈式麦克风常常应用于舞台录音,主要就是为了避免噪声干扰。并且,孙亦廷面前摆放了21个按键可以放大任意一位演唱者的声音,同时孙亦廷也是戴着耳罩式耳机来听声音。
因此节目组特意安排的这种声学场景布局就产生了两个疑问:
孙亦廷听到的声音是每位合唱者的独立音轨通过演播室音响系统混音后的声音(这也有待于确认混音方法),至于孙亦廷的耳机是否包含音乐的混音我们还无法从电视画面中确认。而现场观众听到的声音则会受到演播室音响扩声系统和演播室建筑声学设计的严重影响。电视观众所听到的声音还会受到电视音频编解码系统的严重影响。
即便和现场演示一样也是获得的混音数据,由于机器人可以比人类更方便的放大每一位歌唱者的音频,也是极大减弱了挑战的难度,这对于人类反而不公平了。凡是学过信号处理的同学都清楚,信号处理其实不在意绝对噪声的干扰,理想场景的物理世界是不存在的,只要符合“信噪比”这个指标就能满足机器处理的要求。
所以有篇文章中所提到的“低质量的语音数据,又要在强噪声干扰下对歌唱数据进行识别,对小度来说确实挑战很大”这句话实际上是不准确的。即便“合唱发声差异性极小且互相影响”这句话也不是确定的。
小度机器人听到的声音,孙亦廷听到的声音,现场观众听到的声音和电视机观众听到的声音其实都是不一样的,而且这个难度也是逐渐增加的。后面两种声音其实才是真正的挑战极限,而且这两种极限挑战还存在无解的问题。
因为物理世界和人耳机理存在一些特性,即便现场观众所听到的声音也有两个难点必须考虑到:
(1)演播室音响系统,对于声音的渲染处理会损失原始声音特性或者增强无关特性,这将会加重人耳听到声音的误差。
(2)现场听到的声音,也会收到演播室的建筑声学设计和扩声系统设计的影响,这其中还包括了声学两个特殊效应的制约:
其一就是
哈斯效应(Haas effect; Precedence effect)
,这是一种双耳心理声学效应,声音延迟对人类方向听觉的影响要比能量大小的影响更大的效应,故此也被称为优先效应。
哈斯效应是亥尔姆·哈斯于1949年在他的博士论文中描述的,常常利用哈斯效应来调整会场和音乐厅的声音和谐。举个简单的例子,若你到电影院坐到了靠近音箱的位置,那几乎听到的声音几乎都是附近这个喇叭发出的了。事实上现场观众根本就无法区分21位歌唱者在合唱时候的差别。
其二就是
掩蔽效应(Masking Effect)
,简单说是环境中的其他声音会使人类听觉对某一个声音的听力降低。
当一个声音的强度远比另一个声音大,当大到一定程度而这两个声音同时存在时,人们只能听到音量更大的那个声音存在,而觉察不到另一个声音存在。其中,低频声的掩蔽范围大于高频声的掩蔽范围。也就说,现场观众可能根本就无法辨认出到底有几个歌唱者的声音,何谈再从中识别出特征了。
当然还有更多物理定律和声学模型的制约,
即便上面的哈斯效应和掩蔽效应实际上也造成了现场听众可能无解的情况,因为可能压根就没有获取到所需要的物理信号。
这对于电视机前面的观众就更为苛刻了,因为即便数字电视的音频编解码也是有损压缩的,这实际上又损失了众多声学特征信息,不管是MP3还是AAC都利用了人耳的掩蔽效应进行了压缩,何况电视在家里的摆放同样也无法避免建筑声学和音响系统的制约。
因此,“最强大脑”节目组所追求的难度和效果实际上在执行过程中已经严重折扣了,这次比赛更是考验深度学习算法和人脑识别的差异,而刻意回避了物理感知中的难题,和深度学习在测试集的测试结果没有本质上的差别。
事实上,百度科学家对于这个问题是清晰认识的,百度语音识别技术负责人李先刚坦言:
就现在的深度学习或者相关技术来说,处理同一个麦克风捕捉的多人同时说话的数据确实很难做,还有很多地方值得我们去挑战。但就实际应用场景来说,有其他方法可以较好地解决该问题,比如强化定位,正如人有两个耳朵可以定位声音源,在实际应用中我们可以采用多个麦克风来加强目标声源的声音,这样就能较好地分辨目标声源和周围嘈杂。
吴恩达老师也表示,此次百度在CES上推出的小鱼(Little Fish)机器人中配置了2个麦克风,可以一定程度解决多人说话的问题,未来还可以用4个、7个甚至更多麦克风来处理该问题。这也正是为何我们声智科技一直追求提升声学传感技术的原因所在。
因此,这里小结一下,
以观众所感受的难度来描述实际挑战的难度是有夸大成分的,夸大宣传会误解大家对于技术发展的正确认知,从而拉大了人们预期,这对于国内的研究和产业进步都是非常不利的。
我们从国外媒体中所看到的文章,其风格相比国内都是比较严肃保守的,包括极其风光的谷歌和亚马逊,谷歌选用AlphaGo挑战围棋非常聪明,避过了人工智能的缺点,即便如此也仍然非常谨慎。亚马逊的Echo其实已经非常成功了,但是Echo几乎不提语音识别率的问题,即便对于远场识别尤为关键的麦克风阵列也是排在了次要位置甚少强调,这都是非常聪明的。因为技术的发展还远没有达到国内宣传所夸大的程度。
另外还要补充说下聪明的苹果,大家不要忽视了这位低调的巨头,Siri积累了那么多年,优势是在近场语音交互,而智能耳机就是最好的落地,苹果并没有缺席人工智能,也不会错过下一个计算平台,而是悄悄的把握住了另外一个巨大的市场机会。
2、孙亦廷的挑战更大,小度机器人也展现了百度深度学习的水平
综合上面分析来看,若电视场景中所表现出来的和实际工作过程都是准确如实的(抱歉毕竟只是娱乐节目,而不是公开论文可验证,谷歌的AlphaGo再次聪明的避过了这个验证难题),孙亦廷其实面临的难度要超过百度的小度机器人,若公平来说,人类和机器人所面临的挑战难度都是极大的,百度的小度机器人也展现出来了吴恩达老师带领百度人工智能团队领先的水平。
这个挑战最大的难度在于:节目组设计的挑战是从片段的说话声中辨认出歌唱者。周杰伦给3个歌唱者的对话都是比较简短的,而且这个对话又被简单处理了(只是截取,和加密也没啥关系),我们从爱奇艺的视频中抽取了这三段视频,其声纹特征如下(非现场原始音频,已经被压缩很大,仅供参考):
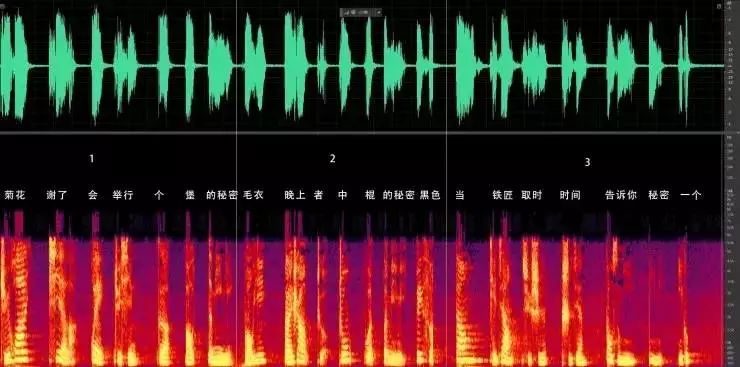
从图中可以看出,三个人的声纹特征差异还是非常明显的。但是这仅仅只是说话的声纹,大部分唱歌的声音和说话的声音都是不同的。我在雷锋网《
声纹识别技术的现状、局限与趋势
》公开课中提到过,声纹识别的理论基础是每一个声音都具有独特的特征,通过该特征能将不同人的声音进行有效的区分,这种独特的特征主要由两个因素决定:





