正文
整体
环境新建
虚机
分配网络还原
在其他节点
(
nc05)成功启动 neutron-dhcp-agent
18:30:00:
放弃在控制节点还原网络服务,尝试在其他节点还原网络服务;
18:00:00:
尝试删除
tap设备,但进度较慢;尝试在代码去掉neutron-openvsiwtch-agent中关于tap设备的预读过程,因涉及点太多放弃在线修改;
17:00:00:
发现控制节点存在10000+tap设备,link状态为DOWN(导致neutorn-openvswitch-agent启动失败
)
;
16:40:00:
整体
环境新建
虚拟机
分配网络
失效
,处理人忙乱之中再次重启neutron-dhcp-agent,发现循环错误,neutron-dhcp-agent重启失败;
16:30:00:
控制节点所属(
6台)
虚拟机网络失效
怀疑是控制节点流表未刷新原因,开发同事尝试重启控制节点的neutron-openvsiwtch-agent刷新,但重启失败;
16:25:00:
开发
开始定位
处理
开发同事检查虚拟机创建成功,但新建虚拟机无法获取neutron-metadata服务接口,导致业务集群配置失败;
16:10:00:
线上
环境更新包
功能
失效
项目维护同事反映培训环境更新业务应用集群失效;
@utils.exception_logger()
def _periodic_resync_helper(self):
"""Resync the dhcp state at the configured interval."""
while True:
eventlet.sleep(self.conf.resync_interval) //间隔时间默认为30s
if self.needs_resync_reasons: // needs_resync_reasons由待决事件更新
# be careful to avoid a race with additions to list
# from other threads
reasons = self.needs_resync_reasons
self.needs_resync_reasons = collections.defaultdict(list)
for net, r in reasons.items():
if not net:
net = "*"
LOG.debug("resync (%(network)s): %(reason)s",
{"reason": r, "network": net})
self.sync_state(reasons.keys())
经过内部环境反复测试与现场日志对比,发现实际产生10000多个tap设备的循环位于neutron-dhcp-agent服务的定时同步功能函数中
下面这段整体逻辑由于一个设置namespace的异常而不断重试循环:
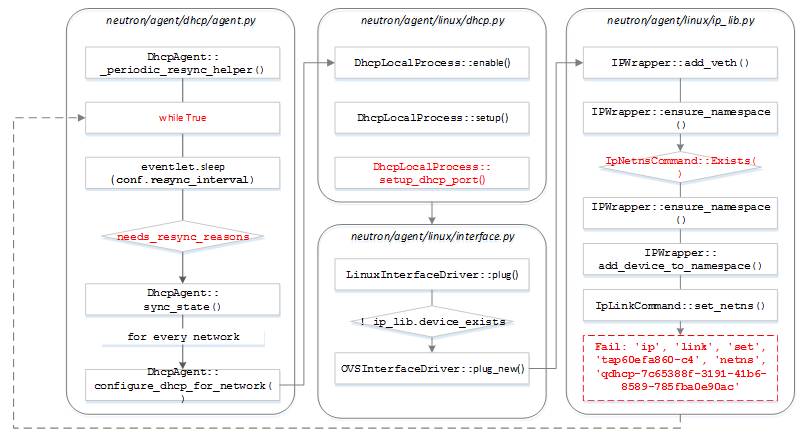
1) Neutron-dhcp-agent循环监听是否存在更新需求(need_resunc_reasons);
2) 每次循环延迟间隔conf.resync_interval秒;
3) setup_dhcp_port()方法中申请一个新的Port(新的tapid产生);
4) add_veth()方法创建veth设备(新的tap设备产生);
5) ensure_namespace()方法中确认namespace,如不存在则创建;
6) set_netns()方法设置tap设备的network namespace,设置失败;
7) 跳转到第一步循环;
可以看到,这段逻辑本身有一定缺陷
1) 设置namespace失败后,没有正确的try...catch流程删除之前创建的设备,导致失败的tap设备积累越来越多
2) ensure_namespace()方法只检查namespace是否存在,没有深入检查namespace权限等可能导致后续设置失败的属性
接下来的问题是(可能也是neutron在最后一步不设防的原因):namespace是neutron-dhcp-agent进程自身创建的,tap设备也是neutron-dhcp-agent进程自身创建的,为什么设置时会失败呢?
N
eutron-
*-agent
各服务需要操作主机共享的network namespace
,在
容器化部署OpenStack
的
场景中,就需要
n
eutron-*-agent
各容器的启动
参数中包含映射参数如:“
-v





