正文
get_comment_message
(product_id)
:
urls = [
'https://sclub.jd.com/comment/productPageComments.action?'
\
'callback=fetchJSON_comment98vv53282&'
\
'productId={}'
\
'&score=0&sortType=5&'
\
'page={}'
\
'&pageSize=10&isShadowSku=0&rid=0&fold=1'
.format(product_id, page)
for
page
in
range(
1
,
11
)]
for
url
in
urls:
response = requests.get(url)
html = response.text
# 删除无用字符
html = html.replace(
'fetchJSON_comment98vv53282('
,
''
).replace(
');'
,
''
)
data = json.loads(html)
comments = data[
'comments'
]
t = threading.Thread(target=save_mongo, args=(comments,))
t.start()
在这个方法中只获取了前10页的评价的url,放到urls这个列表中。
通过循环获取不同页面的评价记录,这时启动了一个线程用来将留言数据存到到MongoDB中。
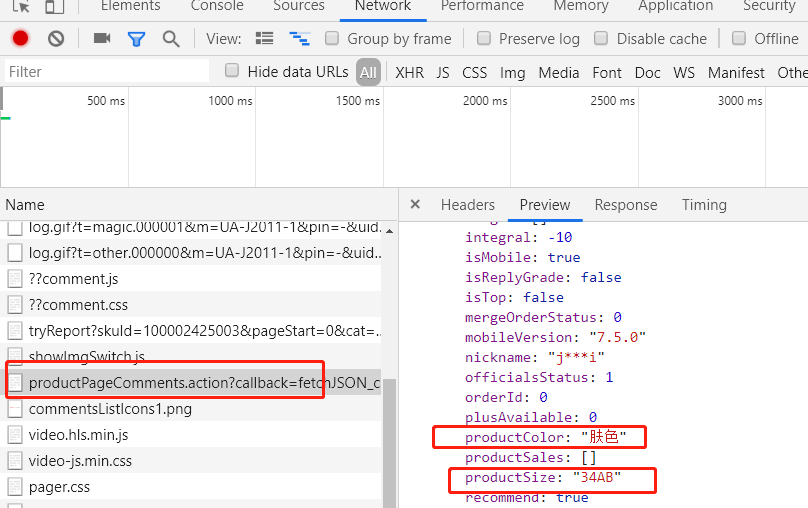
我们继续分析评价记录这个接口发现我们想要的两条数据
productColor:
产品颜色
productSize:
产品尺寸
client = pymongo.MongoClient('mongodb://127.0.0.1:27017/')
db = client.jd
product_db = db.product
def save_mongo(comments):
for comment in comments:
product_data = {}
product_data['product_color'] = flush_data(comment['productColor'])
product_data['product_size'] = flush_data(comment['productSize'])
product_data['comment_content'] = comment['content']
product_data['create_time'] = comment['creationTime']
product_db.insert(product_data)
因为每种商品的颜色、尺寸描述上有差异,为了方面统计,我们进行了简单的数据清洗。这段代码非常的不Pythonic。不过只是一个小demo,大家无视即可。
def flush_data(data):
if '肤'





