正文
变量选择
随机森林最好的用例之一是特征选择。尝试很多决策树变种的一个副产品就是你可以检测每棵树中哪个变量最合适/最糟糕。
当一棵树使用一个变量,而另一棵不使用这个变量,你就可以从是否包含这个变量来比较价值的减少或增加。优秀的随机森林实现将为你做这些事情,所以你需要做的仅仅是知道去看那个方法或参数。
在下述的例子中,我们尝试去指出对于将酒分为红酒或者白酒哪个变量是最重要的。
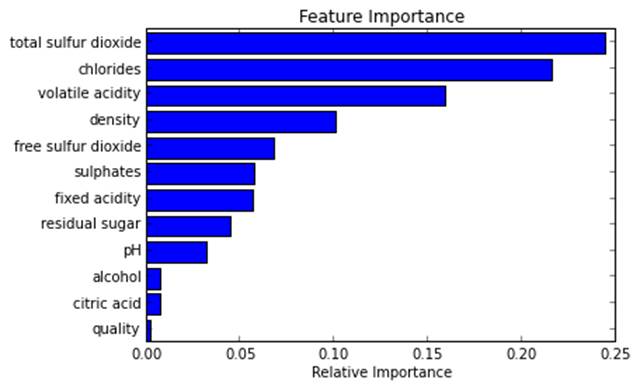
分类
随机森林也很善于分类。它可以被用于为多个可能目标类别做预测,它也可以被校正输出概率。你需要注意的一件事情是过拟合。随机森林容易产生过拟合,特别是在数据集相对小的时候。当你的模型对于测试集合做出“太好”的预测的时候就应该怀疑一下了。
产生过拟合的一个原因是在模型中只使用相关特征。然而只使用相关特征并不总是事先准备好的,使用特征选择(就像前面提到的)可以使其更简单。
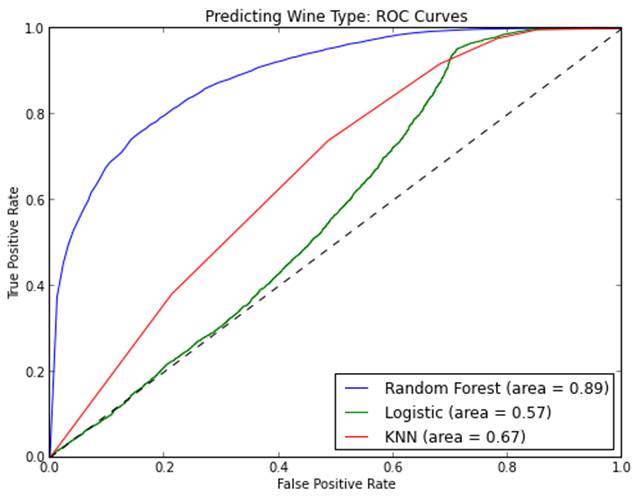
回归
是的,它也可以做回归。
我们已经发现随机森林——不像其它算法——对分类变量或者分类变量和真实变量混合学习的非常好。具有高基数(可能值的#)的分类变量是很棘手的,所以在你的口袋中放点儿这样的东西将会是非常有用的。
Scikit-Learn是开始使用随机森林的一个很好的方式。scikit-learnAPI在所以算法中极其的一致,所有你测试和在不同的模型间切换非常容易。很多时候,我从一些简单的东西开始,然后转移到了随机森林。
随机森林在scikit-learn中的实现最棒的特性是n_jobs参数。这将会基于你想使用的核数自动地并行设置随机森林。这里是scikit-learn的贡献者OlivierGrisel的一个很棒的报告,在这个报告中他谈论了使用20个节点的EC2集群训练随机森林。
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75
df['species'] = pd.Factor(iris.target, iris.target_names)
df.head()
train, test = df[df['is_train']==True], df[df['is_train']==False]
features = df.columns[:4]
clf = RandomForestClassifier(n_jobs=2)
y, _ = pd.factorize(train['species'])
clf.fit(train[features], y)
preds = iris.target_names[clf.predict(test[features])]
pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds'])
看起来很不错!
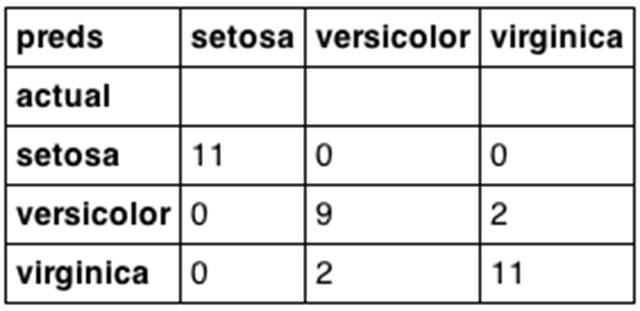
随机森林相当容易使用,而且很强大。对于任何建模,都要注意过拟合。如果你有兴趣用R语言开始使用随机森林,那么就签出randomForest包。
End











