正文
这四种行为,我们为不同的行为赋予分数,就能得到新闻的实时用户行为分为:
S(Users) = 1*click + 5*favor + 10*comment + 20*share
这里对不同行为赋予的分数为1,5,10,20,但这个值不能是一成不变的;当用户规模小的时候,各项事件都小,此时需要提高每个事件的行为分来提升用户行为的影响力;当用户规模变大时,行为分也应该慢慢降低,因此做内容运营时,应该对行为分不断调整。
当然也有偷懒的办法,那就是把用户规模考虑进去,算固定用户数的行为分,即:
S(Users) = (1*click + 5*favor + 10*comment + 20*share)/DAU * N(固定数)
这样就保证了在不同用户规模下,用户行为产生的行为分基本稳定。
2.4 热度随时间的衰减不是线性的
由于新闻的强时效性,已经发布的新闻的热度值必须随着时间流逝而衰减,并且趋势应该是衰减越来越快,直至趋近于零热度。换句话说,如果一条新闻要一直处于很靠前的位置,随着时间的推移它必须要有越来越多的用户来维持。
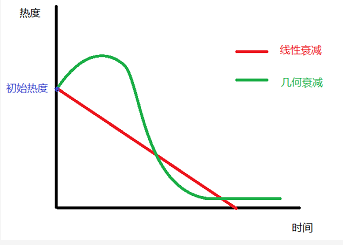
我们要求推荐给用户的新闻必须是24h以内,所以理论上讲,衰减算法必须保证在24h后新闻的热度一定会衰减到很低,如果是线性衰减,当某些新闻突然有大量用户阅读,获得很高的热度分时,可能会持续排名靠前很久,让用户觉得内容更新过慢。
参考牛顿冷却定律,时间衰减因子应该是一个类似于指数函数:
T(Time) = e ^ (k*(T1 – T0))
其中T0是新闻发布时间,T1是当前时间。
而由于热度的发展最终是一个无限趋近于零热度的结果,最终的新闻的热度算法也调整为:
Score = ( S0(Type) + S(Users) ) / T(Time)
2.5 其他影响因素
很多新闻产品会给用户“赞”,“踩”或“不在推荐此类”的选项,这些功能不仅适用于个性化推荐,对热度算法也有一定的作用。
新闻的推送会造成大量的打开,在计算热度的时候需要排除掉相关的影响。类似于这样的因素,都会对热度算法产生影响,因此热度算法上线后,依然需要不断地“调教”。建议把所有的调整指标做成可配项,例如初始热度分,行为事件分,衰减因子等,从而让产品和运营能实时调整和验证效果,达到最佳状态。
现在,你的内容产品顺利度过了早期阶段,拥有了几万甚至十几万级别的日活。这时候,你发现
热度算法导致用户的阅读内容过于集中
,而个性化和长尾化的内容却鲜有人看,看来是时候开展个性化推荐,让用户不仅能读到大家都喜欢的内容,也能读到只有自己感兴趣的内容。
个性化推荐一般有两种通用的解决方案,一是基于内容的相关推荐,二是基于用户的协同过滤。由于基于用户的协同过滤对用户规模有较高要求,因此更多使用基于内容的相关推荐来切入。
这里引入一个概念叫“新闻特征向量”来标识新闻的属性,以及用来对比新闻之间的相似度。我们把新闻看作是所有关键词(标签)的合集,理论上,如果两个新闻的关键词越类似,那两个新闻是相关内容的可能性更高。 新闻特征向量是由新闻包含的所有关键词决定的。得到新闻特征向量的第一步,是要对新闻内容进行到关键词级别的拆分。
3.1 分词
分词需要有两个库,即正常的词库和停用词库。正常词库类似于一本词典,是把内容拆解为词语的标准;停用词库则是在分词过程中需要首先弃掉的内容。
停用词主要是没有实际含义的,例如“The”,“That”,“are”之类的助词;表达两个词直接关系的,例如“behind”,“under”之类的介词,以及很多常用的高频但没有偏向性的动词,例如“think”“give”之类。显而易见,这些词语对于分词没有任何作用,因此在分词前,先把这些内容剔除。
剩下对的内容则使用标准词库进行拆词,拆词方法包含正向匹配拆分,逆向匹配拆分,最少切分等常用算法,这里不做展开。
因为网络世界热词频出, 标准词库和停用词库也需要不断更新和维护,例如“蓝瘦香菇”,“套路满满”之类的词语,可能对最终的效果会产生影响,如果不及时更新到词库里,算法就会“一脸懵逼”了。
因此,推荐在网上查找或购买那些能随时更新的词库,各种语种都有。





