正文
鲸鱼定位
这是为了获得优质的护照照片而迈出的第一步。 为了获得训练数据,我们在训练数据中手动标注了所有的鲸鱼,并用方框圈出了它们的头部(特别感谢我们的人力资源部门帮助!)。

头部定位器得到的头部边框
这些标注为训练集中的每个图像提供四个数字:矩形的左下角和右上角的坐标。然后我们训练一个收到原始图像(调整为256×256)的CNN并输出边界框的两个坐标。虽然这显然是一个回归的任务,但我们并未使用L2损失函数,而是将输出量化分组并使用Softmax以及交叉熵损失函数,并取得了更大的成功。我们还尝试了几种不同的方法,包括训练CNN来区分头部照片和非头部照片,甚至是一些非监督方法。然而,他们的结果却逊色不少。
此外,头部定位网络还必须预测喷水孔和帽尖的坐标(以相同的量化方式),但是在这个任务中不太成功,所以我们忽略了这个输出。
我们训练了5个不同的网络,架构基本相同。
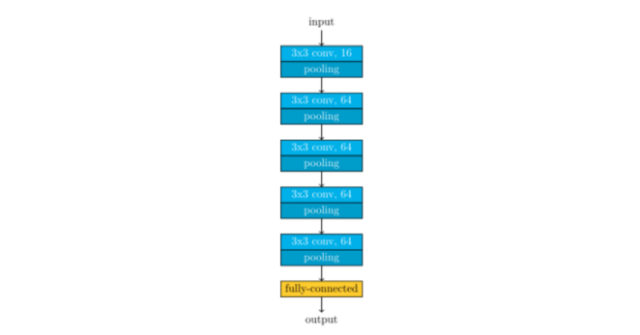
头部定位器的构架
这5个网络不同之处在于用于量化坐标的buckets的数量。我们尝试了20,40,60,128,还有另外一个较小的网络用了20个buckets。
在将图像输入网络之前,我们进行了数据增强(调整到256 x 256以后)。
虽然我们没有采用测试时增强技术,但我们将所有5个网络的输出相结合,即每次裁剪后的图片传到下一步(头部校准)时,我们会在5个网络的输出结果中随机选择一个。如上所述,这些网络的裁剪结果非常令人满意。实际上,我们并没有真正“物理地”裁剪图像(即产生一堆更小的图像),我们所做的(事实证明也是非常方便的)只是生成一个含有边框信息的json文件。这可能是无关紧要的,但是这样让我们能够轻松进行试验。
鲸鱼的“护照照片”
分类器的最后一步就是调整照片,使他们都符合相同的标准。基本的想法是训练一个CNN来估计喷水孔和帽尖的坐标。有了这些坐标,就可以很容易构造变换,使得原始图像变换为这两个点总是处于相同的位置(即头部校准)。由于Anil Thomas的标注,我们有了训练集的坐标。所以,我们再次训练CNN来预测量化坐标。虽然使用整个图像来确定这些点也是可能的(即跳过头部定位的步骤),但通过前面的操作我们可以更容易得实现头部校准。





