正文

图 1.3.1 Oberver 接口定义
先看通过 Histogram 采集一个 float64 数据的 Observe 方法实现(图 1.3.2)。
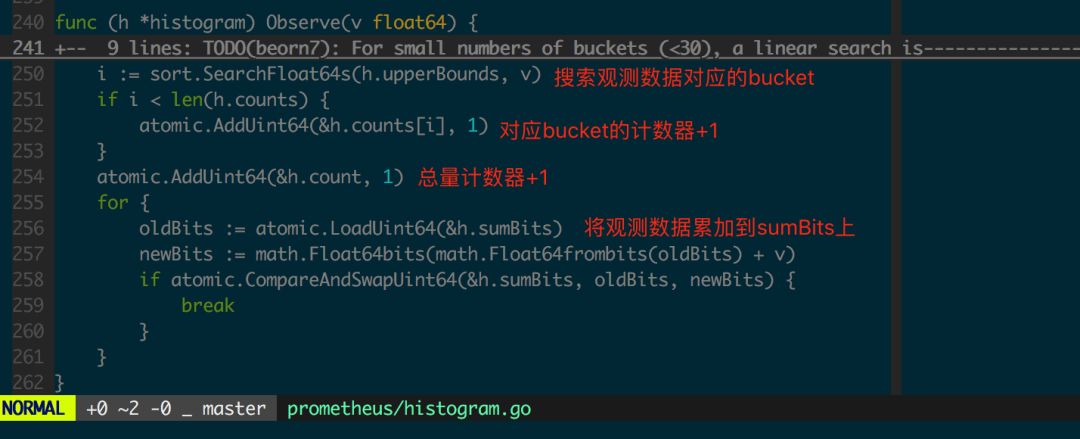
图 1.3.2 histogram.Observe
此处每个 bucket 对应的 count 是不互相包含的,bucket 的计数器之和应该等于全局计数器,即 h.count == sum(h.counts) 是成立的。然而为了便于服务端存储和计算,最终服务端收集到的数据是向下包含的,这是在 histogram.Write(图 1.3.3)中实现的。

图 1.3.3 histogram.Write 实现
图 1.3.4 中用表格形式给出了 Histogram 采集和整理数据的过程。

图 1.3.4 Histogram 采集整理数据过程实例
Histogram 在客户端也是无锁的,因为每个采样点只更新一个具体 bucket 内的 Counter(float64),因此客户端性能开销相比 Counter 和 Gauge 而言没有明显改变,适合高并发的数据收集。
图 1.3.5 为 Go 客户端的 Histogram 默认 bucket 设置,可以用来采集 Web 服务响应时间,实际应用中通常需要为监控对象选择合理的 buckets,buckets 应设置为正态分布中常用的分位点。
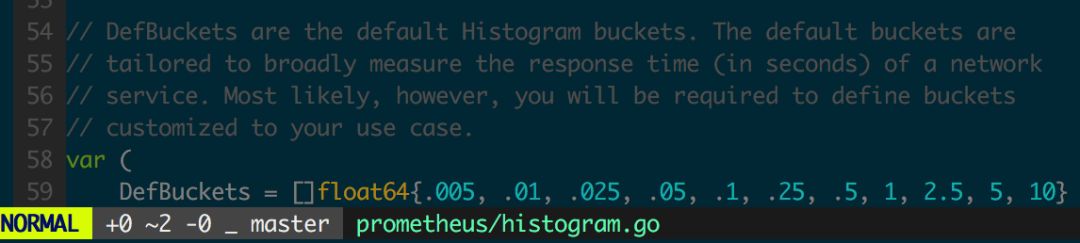
图 1.3.5 histogram 默认 buckets 设置
Summary 是标准数据结构中最复杂的一个,用来收集服从正态分布的采样数据。在 Go 客户端 Summary 结构和 Histogram 一样,都实现了 Observer 接口(图 1.3.1)。
Summary 中 quantile 实际上是正态分布中的分位点 ,如图 1.4.1 所示,图中的实心圆点分别代表 [0.025 0.25 0.50 0.75 0.975] 分位点,图 2.1.10 中 0.5 分位点的采样数据为 0,而 0.975 分位点的采样值为 2,这说明采样数据的绝大部分的峰值都在 2 附近。
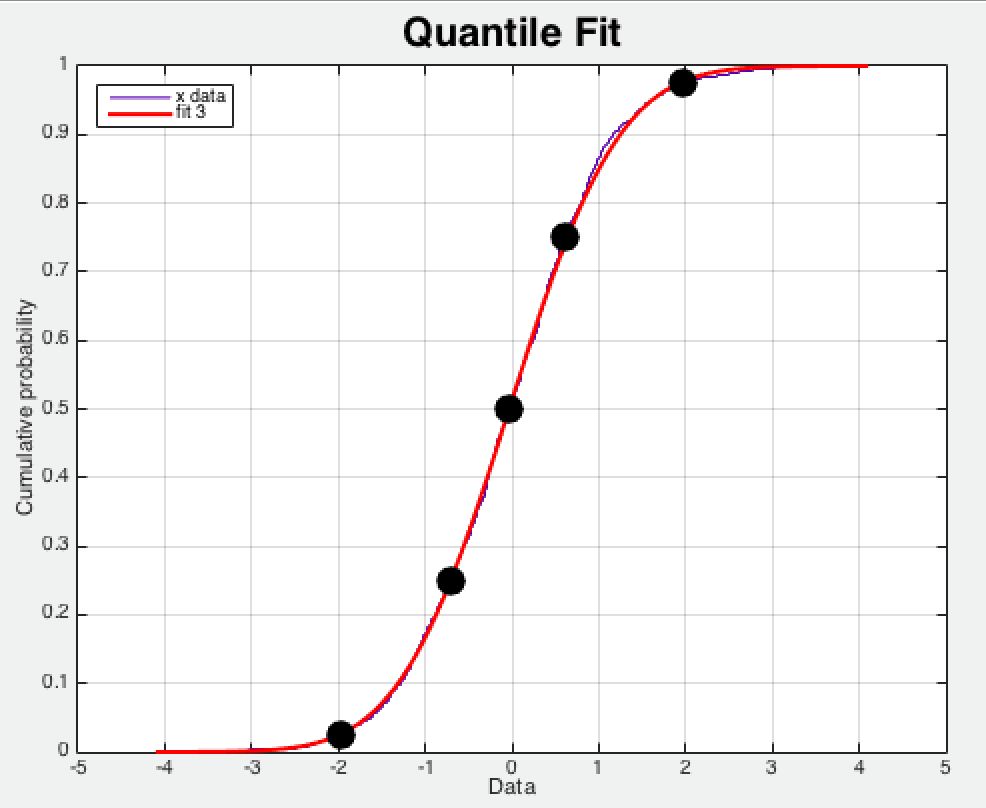
图 1.4.1 随机正态分布数据的Quantile逼近仿真
由于 Summary 结构的客户端实现相比其他几个结构而言复杂一些,先看一下 summary 结构的定义(图 1.4.2)。
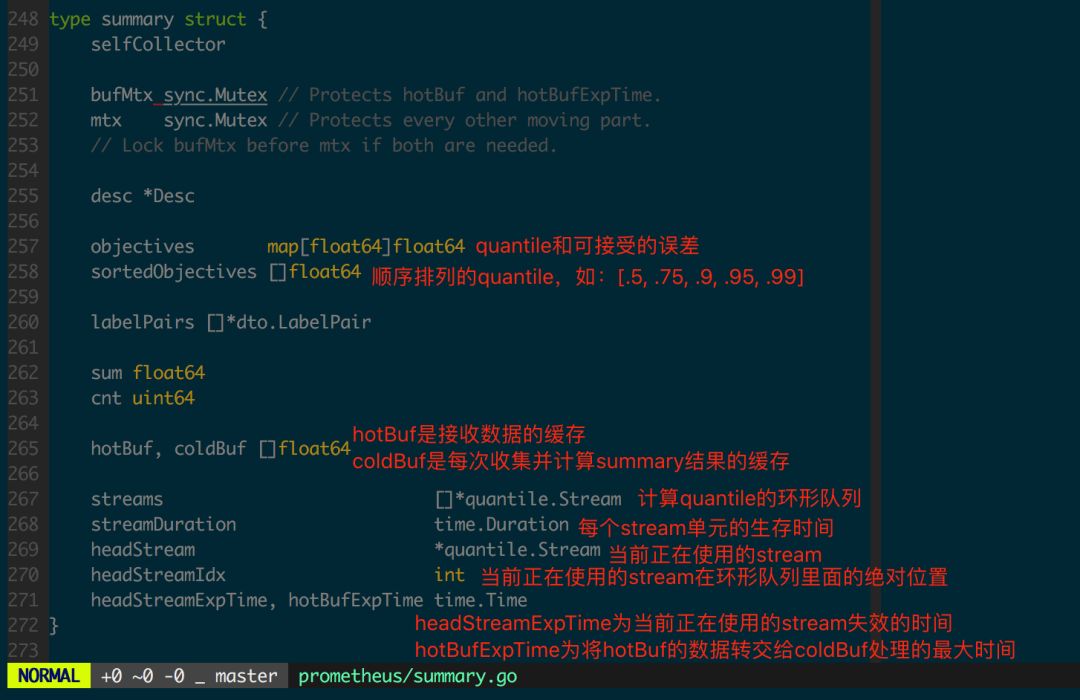
图 1.4.2 summary 定义
Summary 会将采集到的数据经过正态分布逼近得出对应分位点的采样数据,数据流如图 1.4.3 所示。
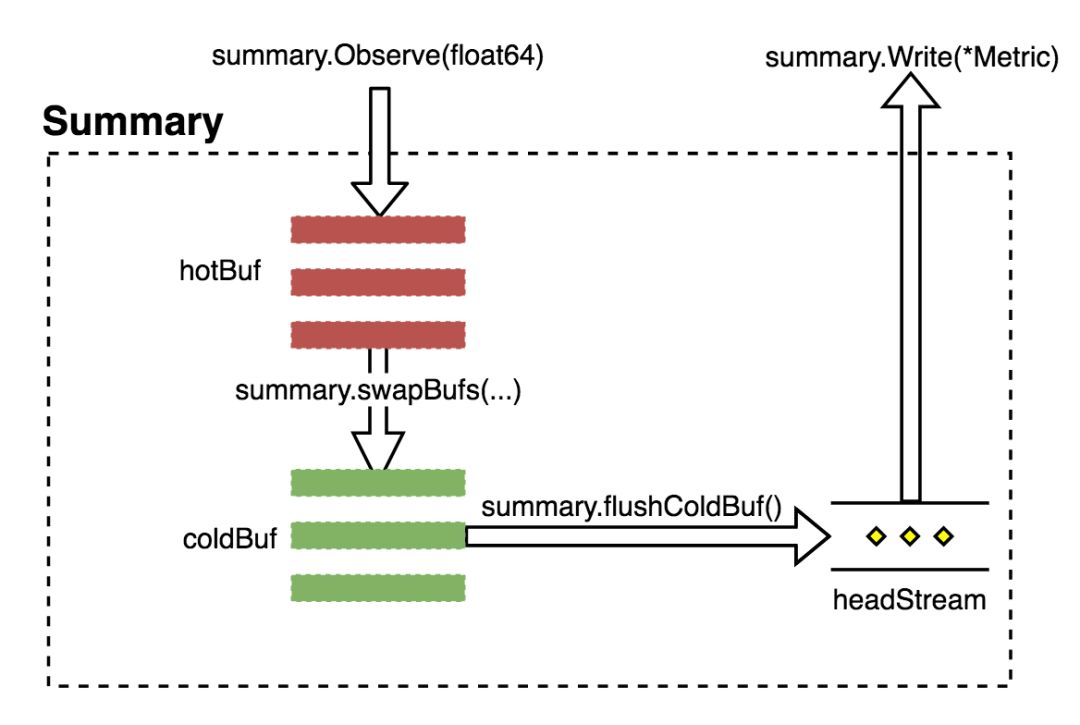
图 1.4.3 Summary 数据流
接下来看 summary.Observe 实现,图 1.4.4 和 1.4.5 中加入了代码逻辑的注解。
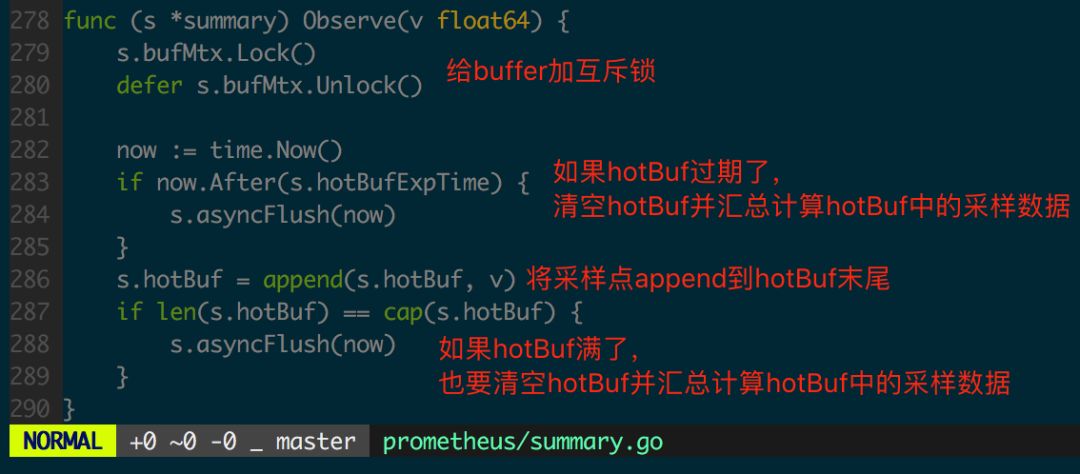
图 1.4.4 summary.Observe 实现
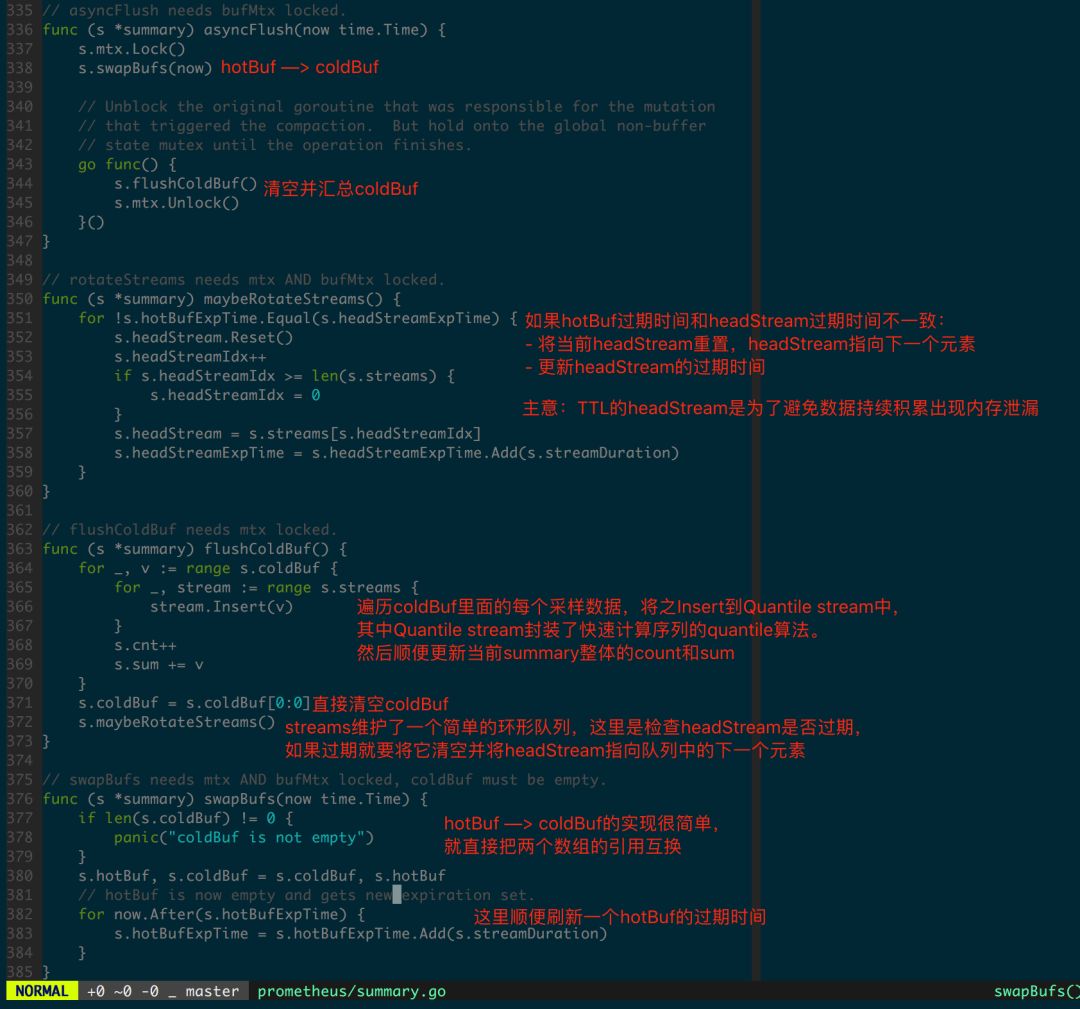
图 1.4.5 summary.asyncFlush 的实现
再看 summary.Write 实现,图 1.4.6 中加入了代码逻辑的注解。

图 1.4.6 summary.Write 实现
客户端集成时,需要关注采集监控数据对程序性能和可靠性的影响,同时也需要关注数据完备性,即采集到的数据应完整、正确地反映监控对象的状态和变化,笔者提出以下两点思路:







