正文
-
回归问题
-
分类问题
(二分类、多分类、多标签)
多分类只需从多个类别中预测一个类别,而多标签则需要预测出多个类别。
比如Quora的比赛就是二分类问题,因为只需要判断两个问句的语义是否相似。
1.2 数据分析(Data Exploration)
所谓数据挖掘,当然是要从数据中去挖掘我们想要的东西,我们需要通过人为地去分析数据,才可以发现数据中存在的问题和特征。我们需要在观察数据的过程中思考以下几个问题:
-
数据应该怎么清洗和处理才是合理的?
-
根据数据的类型可以挖掘怎样的特征?
-
数据之间的哪些特征会对标签的预测有帮助?
1.2.1 统计分析
对于数值类变量(Numerical Variable),我们可以得到min,max,mean,meduim,std等统计量,用pandas可以方便地完成,结果如下:
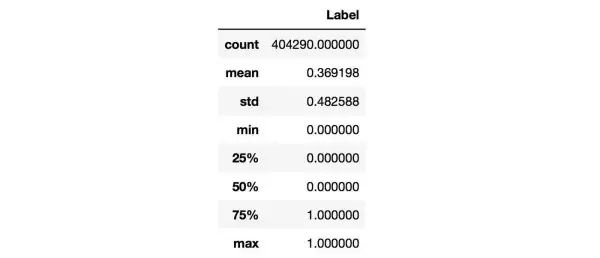 从上图中可以观察Label是否均衡,如果不均衡则需要进行over sample少数类,或者down sample多数类。我们还可以统计Numerical Variable之间的相关系数,用pandas就可以轻松获得
相关系数矩阵
:
从上图中可以观察Label是否均衡,如果不均衡则需要进行over sample少数类,或者down sample多数类。我们还可以统计Numerical Variable之间的相关系数,用pandas就可以轻松获得
相关系数矩阵
:
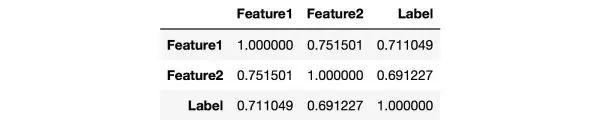
观察相关系数矩阵可以让你找到高相关的特征,以及特征之间的冗余度。而对于文本变量,可以统计词频(TF),TF-IDF,文本长度等等,更详细的内容可以参考这里:
http://link.zhihu.com/?target=https%3A//www.kaggle.com/sudalairajkumar/simple-leaky-exploration-notebook-quora%3FscriptVersionId%3D1184830
1.2.2 可视化
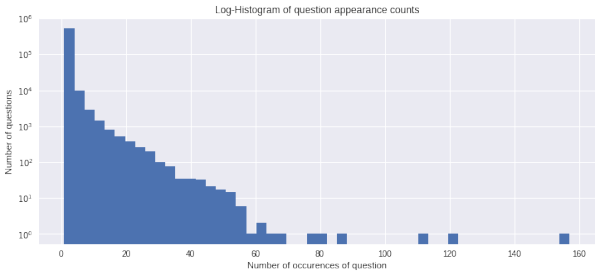
人是视觉动物,更容易接受图形化的表示,因此可以将一些统计信息通过图表的形式展示出来,方便我们观察和发现。比如用直方图展示问句的频数:
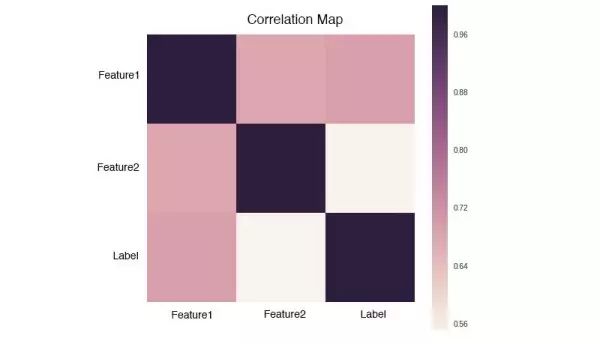
 或者绘制相关系数矩阵:
或者绘制相关系数矩阵:
 常用的可视化工具有matplotlib和seaborn。当然,你也可以跳过这一步,因为可视化不是解决问题的重点。
常用的可视化工具有matplotlib和seaborn。当然,你也可以跳过这一步,因为可视化不是解决问题的重点。
1.3 数据预处理(Data Preprocessing)
刚拿到手的数据会出现噪声,缺失,脏乱等现象,我们需要对数据进行清洗与加工,从而方便进行后续的工作。针对不同类型的变量,会有不同的清洗和处理方法:
-
对于数值型变量(Numerical Variable),需要处理离群点,缺失值,异常值等情况。
-
对于类别型变量(Categorical Variable),可以转化为one-hot编码。
-
文本数据是较难处理的数据类型,文本中会有垃圾字符,错别字(词),数学公式,不统一单位和日期格式等。我们还需要处理标点符号,分词,去停用词,对于英文文本可能还要词性还原(lemmatize),抽取词干(stem)等等。
1.4 特征工程(Feature Engineering)
都说特征为王,特征是决定效果最关键的一环。
我们需要通过探索数据,利用人为先验知识,从数据中总结出特征。
1.4.1 特征抽取(Feature Extraction)
我们应该尽可能多地抽取特征,只要你认为某个特征对解决问题有帮助,它就可以成为一个特征。
特征抽取需要不断迭代,是最为烧脑的环节,它会在整个比赛周期折磨你,但这是比赛取胜的关键,它值得你耗费大量的时间。
那问题来了,怎么去发现特征呢?光盯着数据集肯定是不行的。如果你是新手,可以先耗费一些时间在Forum上,看看别人是怎么做Feature Extraction的,并且多思考。虽然Feature Extraction特别讲究经验,但其实还是有章可循的:
-
对于Numerical Variable,可以通过线性组合、多项式组合来发现新的Feature。
-
对于文本数据,有一些常规的Feature。比如,文本长度,Embeddings,TF-IDF,LDA,LSI等,你甚至可以用深度学习提取文本特征(隐藏层)。
-
如果你想对数据有更深入的了解,可以通过思考数据集的构造过程来发现一些magic feature,这些特征有可能会大大提升效果。在Quora这次比赛中,就有人公布了一些magic feature。
-
通过
错误分析
也可以发现新的特征(见1.5.2小节)。
1.4.2 特征选择(Feature Selection)
在做特征抽取的时候,我们是尽可能地抽取更多的Feature,但过多的Feature会造成冗余,噪声,容易过拟合等问题,因此我们需要进行特征筛选。特征选择可以加快模型的训练速度,甚至还可以提升效果。
特征选择的方法多种多样,最简单的是相关度系数(Correlation coefficient),它主要是衡量两个变量之间的线性关系,数值在[-1.0, 1.0]区间中。
数值越是接近0,两个变量越是线性不相关。但是数值为0,并不能说明两个变量不相关,只是线性不相关而已。
我们通过一个例子来学习一下怎么分析相关系数矩阵:
相关系数矩阵是一个对称矩阵,所以只需要关注矩阵的左下角或者右上角。我们可以拆成两点来看:
-
Feature和Label的相关度可以看作是该Feature的重要度,越接近1或-1就越好。
-
Feature和Feature之间的相关度要低,如果两个Feature的相关度很高,就有可能存在冗余。
除此之外,还训练模型来筛选特征,比如L1、L2惩罚项的Linear Model,Random Forest,GDBT等,它们都可以输出特征的重要度。在这次比赛中,我们对上述方法都进行了尝试,将不同方法的平均重要度作为最终参考指标,筛选掉得分低的特征。










