正文
如果我们要训练一个模型来执行新的任务,例如检测骑自行车的人,我们甚至不能够使用已有的模型,因为任务之间的标签都是不一样的。
迁移学习允许我们通过借用已经存在的一些相关的任务或域的标签数据来处理这些场景。我们尝试着把在源域中解决源任务时获得的知识存储下来,并将其应用在我们感兴趣的目标域中的目标任务上去,如图 2 所示。
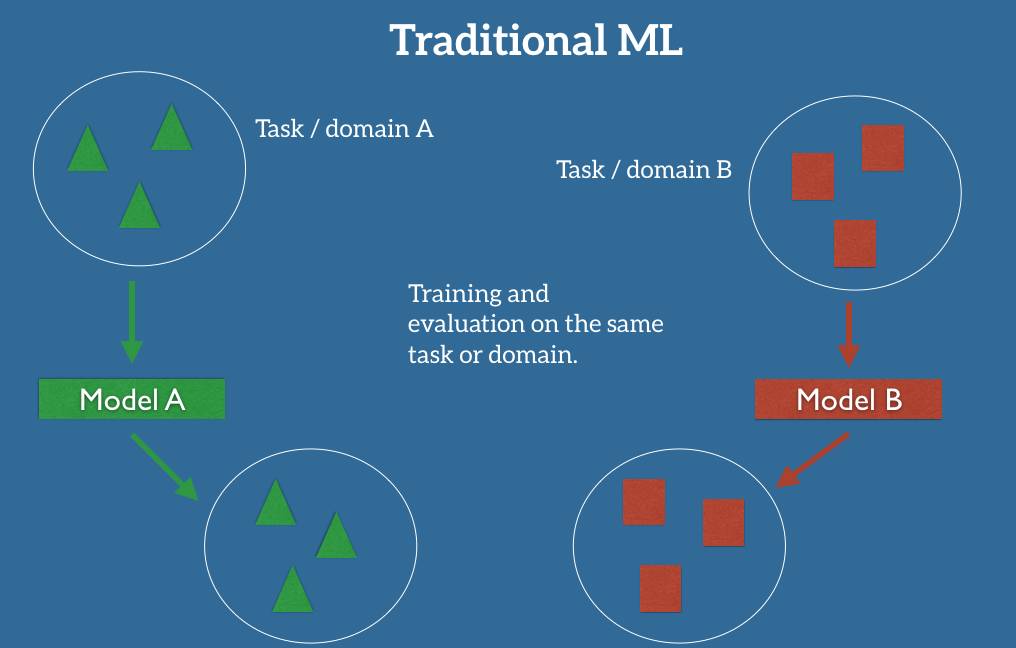
图 2:迁移学习的设置
在实践中,我们力求将尽可能多的知识从源环境迁移到目标任务和域中。依据数据的不同,这种知识有不同的形式:它可以涉及物体是如何组成的,以允许我们更加容易地识别新的对象;也可以是关于人们用来表达观点的普通词汇,等等。
为什么现在需要迁移学习?
前百度首席科学家、斯坦福的教授吴恩达(Andrew Ng)在
广受流传的 2016 年 NIPS 会议的教程中
曾经说过:「迁移学习将会是继监督学习之后的下一个机器学习商业成功的驱动力」。

图 3:吴恩达在 2016 年 NIPS 上谈论迁移学习
特别地,他在白板上画了一个图表,我尽可能忠实地将它复制在如下所示的图 4 中(抱歉坐标轴没有详细的标注)。据吴恩达说,迁移学习将成为机器学习在产业界取得成功的一个关键驱动力。
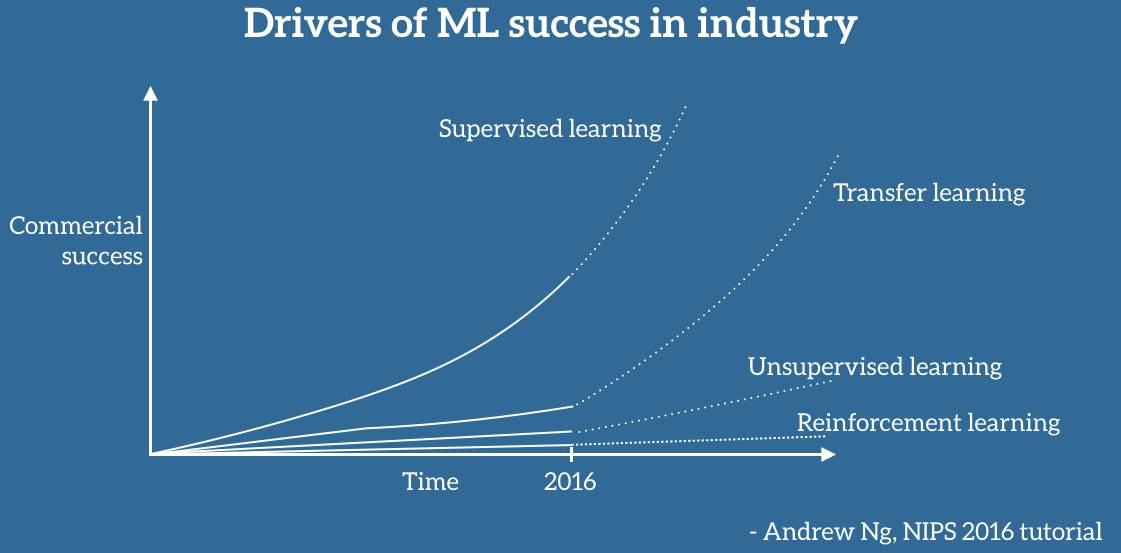
图 4:吴恩达心中机器学习产业成功的驱动力
不容置疑,机器学习在产业界的应用和成功主要是受监督学习的驱动。受到深度学习中的进步、更强大的计算资源以及大量的标签数据集的推动,监督学习是人们对人工智能的兴趣复苏浪潮、多轮融资以及收购的主要原因,尤其是我们近年来看到的机器学习的应用,它们已经成为了我们生活的一部分。如果我们忽视关于另一个人工智能寒冬的怀疑和传言,并且相信吴恩达的预见,这种成功很可能会持续下去。
然而,不太清楚为什么已经存在了大约几十年并且至今在产业界很少被使用的迁移学习会出现吴恩达所预言的那种爆炸式增长。更有甚者,与机器学习的其他领域(如无监督学习和强化学习等)相比,迁移学习目前受到的关注更少。而且那些领域也正越来越受欢迎:无监督学习是实现通用人工智能的关键成分(如图 5 中 Yann LeCun 所说),人们对此兴趣已经复苏,尤其是在生成对抗网络(GAN)的推动下。反过来,强化学习在 Google DeepMind 的牵头下已经实现游戏 AI 的进步,AlphaGo 的成功堪称典范,并且也早已在现实世界中实现了成功,例如将 Google 数据中心的冷却费用降低了 40%。这两个领域虽然很有希望,但是在可预见的未来可能只会有着相对较小的商业影响力,并且大部分还停留在前沿研究论文的范围之内,因为它们仍然面临着许多挑战。

图 5:显然迁移学习没有出现在 Yann LeCun 的蛋糕成分问题中
什么使得迁移学习与众不同呢?下面我们会看一下在我看来驱使了吴恩达的预见的因素,并且总结一下现在正是重视迁移学习的时机的原因。
目前产业界对机器学习的应用分为两类:
一方面,在过去几年中,我们已经获得了训练越来越准确的模型的能力。我们现在所处的阶段,对很多任务而言,最先进的模型已经达到了这样的水平:它们的表现是如此的好以至于对使用者来说不再有障碍了。有多么好呢?最新的 ImageNet 上的残差网络 [1] 在进行物体识别时实现了超越人类的性能;Google 的 Smart Reply 系统 [2] 可以处理所有移动手机中的回复的 10%;语音识别的错误率在持续降低,并且比键盘输入更加准确 [3];我们已经实现了和皮肤科医师一样好的自动皮肤癌识别;Google 的神经机器翻译系统(NMT)[4] 已被用在了超过 10 种以上的语言对的生产中;百度可以实时地生成逼真的语音;类似的还有很多很多。这种成熟度允许将这些模型大规模地部署到数百万的用户上,并且已经得到了广泛的采用。
另一方面,这些成功的模型都是极其地重视数据的,依靠大量的标签数据来实现它们的性能。对一些任务和域而言,经过了多年的精心收集,这种数据是可以得到的。在少数情况下,数据是公开的,例如 ImageNet[5],但是在很多语音或者 MT 的数据集中,大量的标签数据都是有专利的,或者是很昂贵的,因为它们在竞争中提供了前沿参考。
同时,把机器学习的模型应用在自然环境中时,模型会面临大量之前未曾遇到的条件,它不知道如何去处理;每一个用户都有他们自己的偏好,也需要处理和生成不同于之前用来训练的数据;要求模型执行很多和训练相关但是不相同的任务。在所有这些情况下,尽管我们最先进的模型在它们被训练的任务和域上展示出了和人类一样甚至超越人类的性能,然而还是遭遇了明显的表现下降甚至完全失败。
迁移学习可以帮助我们处理这些全新的场景,它是机器学习在没有大量标签数据的任务和域中规模化应用所必须的。到目前为止,我们已经把我们的模型应用在了能够容易获取数据的任务和域中。为了应对分布的长尾,我们必须学会把已经学到的知识迁移到新的任务和域中。
为了做到这个,我们需要理解迁移学习所涉及到的概念。基于这个原因,我会在下面的内容中给出更加技术性的定义。
迁移学习的定义
为了这个定义,我会紧密地遵循 Pan 和 Yang(2010) 所做的杰出的综述 [6],并以一个二元文档分类为例。
迁移学习涉及到域和任务的概念。一个域 D 由一个特征空间 X 和特征空间上的边际概率分布 P(X) 组成,其中 X=x1,…, xn∈X。对于有很多词袋表征(bag-of-words representation)的文档分类,X 是所有文档表征的空间,xi 是第 i 个单词的二进制特征,X 是一个特定的文档。(
注:这里的 X 有两种不同的形式,这里不太好呈现,具体请参考原文。
)
给定一个域 D={X,P(X)},一个任务 T 由一个标签空间 y 以及一个条件概率分布 P(Y|X) 构成,这个条件概率分布通常是从由特征—标签对 xi∈X,yi∈Y 组成的训练数据中学习得到。在我们的文档分类的例子中,Y 是所有标签的集合(即真(True)或假(False)),yi 要么为真,要么为假。
给定一个源域 Ds,一个对应的源任务 Ts,还有目标域 Dt,以及目标任务 Tt,现在,迁移学习的目的就是:在 Ds≠Dt,Ts≠Tt 的情况下,让我们在具备来源于 Ds 和 Ts 的信息时,学习得到目标域 Dt 中的条件概率分布 P(Yt|Xt)。绝大多数情况下,假设可以获得的有标签的目标样本是有限的,有标签的目标样本远少于源样本。
由于域 D 和任务 T 都被定义为元组(tuple),所以这些不平衡就会带来四个迁移学习的场景,我们将在下面讨论。
迁移学习的场景
给定源域和目标域 Ds 和 Dt,其中,D={X,P(X)},并且给定源任务和目标任务 Ts 和 Tt,其中 T={Y,P(Y|X)}。源和目标的情况可以以四种方式变化,我们仍然以我们的文档分类的例子在下面描述:
-
XS≠XT。源域和目标域的特征空间不同,例如,文档是用两种不同的语言写的。在自然语言处理的背景下,这通常被称为跨语言适应(cross-lingual adaptation)。










