正文
当你终于在工作空间中获得数据以后,你要做的第一件事就是赶紧上手。然而,既然你现在对付的是时间序列数据,这看起来便可能不是很直接了,因为你的行标签中带有了时间值。
但是,请别担心!让我们首先按部就班地利用一些函数开始探索数据,如果你先前已经有了一些R的编程经验,或者你已经使用过Pandas, 你可能已经对这些函数有所了解了。
无论哪种情况,你都会觉得这非常简单!
正如你在下面的代码中看到的,你已经用过pandas_datareader来输入数据到工作空间中,得到的对象aapl是一个数据框(DataFrame),也就是一个二维带标记的数据结构,它的每一列都有可能是不同的数据类型。现在,当你手头有一个规则的数据框的时候,你可能首先要做的事情之一就是利用head() 和tail() 函数窥视一下数据框的第一和最后一行。幸运的是,当你处理时间序列数据的时候,这一点是不变的。
小贴士:也可以利用describe() 函数来获取一些有用的总结性统计数据
请从这里找到一些附带的练习
正如你在介绍部分所看到的,数据清楚地包含了四个列,包括苹果的股票每天的开盘价和收盘价,和极高和极低的价格变动。此外,你还得到了两个额外的列:Volume 和Adj Close。前一个列是用来记录在这一天内交易的股权总量。后者则是调整的收盘价格:当天的收盘价格经过细微的调整以适应在后一天开盘前所发生的任何操作。你可以使用这一个列来检验历史回报或者对历史回报做一些细致的分析。
前一个列是用来记录在这一天内交易的股权总量。后者则是调整的收盘价格:当天的收盘价格经过细微的调整以适应在后一天开盘前所发生的任何操作。你可以使用这一个列来检验历史回报或者对历史回报做一些细致的分析。
请注意行标签是如何包含日期信息的,以及你的列和列标签是如何包含了数值数据的。
小贴士:如果你现在想要使用pandas 的to_csv()函数把这些数据存储为csv格式的文件,或是通过read_csv()函数把数据读入回Python。这一点在一些特定场景下是极其便利的,例如说Yahoo API终端发生了变动,你难以再次获取数据的情况。
现在,你已经简要地检查了你的数据的第一行,并且已经查看了一些总结性统计数据,现在我们可以稍微深入一步了。
做这件事的一种方法是通过筛选,例如说某一个列的最后十行数据来检查行标签和列标签。后者则被称为取子集,因为你得到的是数据中的一个小的自己。取子集得到的结果是一个序列,也就是一个带标签的,可以是任何数据类型的一维数组。
请记住,DataFrame结构是一个二维标记的数组,它的列中可能包含不同类型的数据。
在下面的练习中,将检查各种类型的数据。首先,使用index和columns属性来查看数据的索引和列。接下来,通过只选择DataFrame的最近10次观察来取close列的子集。使用方括号[ ]来分隔这最后的十个值。您可能已经从其他编程语言(例如R)中了解了这种取子集的方法。总而言之,将后者分配给变量ts,然后使用该type()函数来检查ts的类型。您可以在这里进行练习。
方括号可以很好地对数据进行取子集,但这可能不是使用Pandas最习惯的做法。这就是为什么您还应该看看loc()和iloc()函数:您可以使用前者进行基于标签的索引,后者可用于位置索引。
在实践中,这意味着您可以将行标签(如标签2007和2006-11-01)传递到loc()函数,同时传递整数(如22与43)到iloc()函数。
完成原文中的练习,了解loc()和iloc()两者是如何工作的。
小贴士:如果您仔细查看子集的结果,您会注意到数据中缺少某些日期; 如果您仔细观察这个模式,您会发现通常缺少两三天;这些天通常是周末或公共假期,这些并不是您需要的数据。没有什么可担心的:它完全正常,您不必补全这些缺失的日期。
除了索引之外,您还可能想要探索一些其他技术来更好地了解您的数据。您永远不知道还会出现什么。我们尝试从数据集中抽取大约20行,然后对数据进行重新采样,使得aapl按照每月进行采样而不是每天采样。您可以利用sample()和resample()函数来完成这项功能。
非常简单直接,不是吗?
resample()函数经常被使用,因为它为您的时间序列的频率转换提供了精细的控制和更多的灵活性:除了自己指定新的时间间隔,并指定如何处理丢失的数据之外,还可以选择指示如何重新取样您的数据,您可以在上面的代码示例中看到。这与asfreq()方法形成清晰的对比,它只有前面两种选择。
小贴士:在上述DataCamp Light块的IPython控制台中自己尝试一下。传递aapl.asfreq("M", method="bfill")看看会发生什么!
最后,在您将数据探索提升到一个新的水平之前,请先可视化您的数据并对数据执行一些常见财务分析,您可能已经开始计算每天开盘价和收盘价之间的差额。您可以在Pandas的帮助下轻松执行这项算术运算;只需将aapl数据Close列的值减去Open列的值。或者说,aapl.Close减去aapl.Open。您可以在aapl DataFrame中创建一个新的叫做diff的列存储结果,然后使用del再次删除它。
小贴士:请确保注释掉最后一行代码,以便aapl DataFrame 的新列不会被删除,这样您可以检查算术运算的结果!
当然,以绝对的方式知道了收益,可能已经帮助您了解您是否做出了一个好的投资,但作为一个金融分析师,您可能会对更有力地衡量股票价值更有兴趣,比如某种股票的价值大幅上涨或下跌了多少。这样做的一个方法是计算每日的百分比变化。
现在知道这一点很好,但不要担心; 您会进一步深入它!
本节介绍了一些您在开始执行先验分析之前,可以首先探索数据的方法。但是,在这方面您还可以走得更远。如果您想了解更多,请考虑使用我们的
Python Exploratory Data Analysis
。
下一步,将使用head(),tail(),索引等等探索您的数据。您可能还需要将您的时间序列数据可视化。Pandas的绘图整合了Matplotlib,使得这项任务变得容易; 只需使用plot()函数并传递相关参数即可。此外,您还可以使用grid参数用以指示在绘图的背景中添加网格。
如果您在原文
中运行代码,您将会看到以下图表:
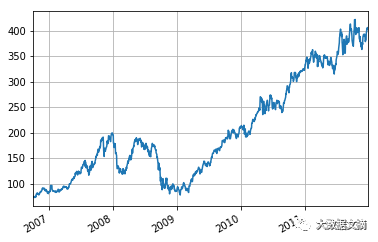
如果您想对Matplotlib了解更多,以及如何开始使用它,请查看DataCamp的Intermediate Python for Data Science课程。
现在,您已经了解了数据,时间序列数据以及如何使用pandas快速浏览数据,现在是深入了解一些您可以做的常见财务分析的时候了,以便您可以开始制定交易策略。
在本节的其余部分,您将了解有关回退、移动窗口、波动率计算和普通最小二乘回归(OLS)的更多信息。
您可以在原文中阅读并练习更多关于常见财务分析的内容。
现在您对数据做了一些初步分析,现在是制定您的第一个交易策略的时候了;但在您进入所有这些之前,为什么不先了解一些最常见的交易策略呢?经过简短介绍,您无疑将更简单地实现您的交易策略。
您可能还记得,在介绍中,交易策略是一个关于长期或短期进入市场的固定计划,但还有更多的信息您还没有真正得到;一般来说,有两个常见的交易策略:动量策略和震荡策略。
首先,动量策略也被称为分离或趋势交易。当您遵循这一策略时,您会这样做的原因是您认为数据的移动将继续朝着当前的方向发展。换句话说,您相信股票有可以发现和利用的惯性,即向上或向下的趋势。
这个策略的一些例子是移动均线交叉,双均线交叉和海龟交易:
移动均线交叉发生在资产的价格从移动平均线的一边移动到另一边的时候。这种交叉代表了势头的变化,可以作为进入或退出市场的决定点。您会看到这个策略的一个例子,本教程后面的定量交易的“您好世界”。
双均线交叉发生在短期平均线跨越长期平均线时。该信号用于识别正在短期平均线的方向上移动的惯性。当短期平均线跨越长期平均线并处于其上方时,产生买入信号,而卖出信号是由短期平均过往长期平均线而低于平均水平触发的。
海龟交易最初是由Richard Dennis教导的一个众所周知的趋势跟踪交易。其基本策略是买入20日高点和卖出20天低点的期货。










