正文
文本摘要也是一个非常经典的 NLP 任务,应用场景非常广泛。我们通常将文本摘要方法分为两类,extractive 抽取式摘要和 abstractive 生成式摘要。前者是从一篇文档或者多篇文档中通过排序找出最有信息量的句子,组合成摘要;后者类似人类编辑一样,通过理解全文的内容,然后用简练的话将全文概括出来。在应用中,extractive 摘要方法更加实用一些,也被广泛使用,但在连贯性、一致性上存在一定的问题,需要进行一些后处理;abstractive 摘要方法可以很好地解决这些问题,但研究起来非常困难。
也是基于
Seq2Seq
+attention 模型在 nmt 任务中的成功,2016 年有很多的工作都是套用
Seq2Seq
+attention 来做 abstractive 摘要任务,取得了一定的突破,但做的任务比较简单,输入是一句比较长的话(比如新闻的开头部分),目标是生成一个标题(比如新闻的标题)。直接套用
Seq2Seq
模型可以得到不错的效果,但 OOV(未登录词)问题是一个棘手的问题,在这个领域提出了 Pointer、CopyNet 等优秀的工作,这类模型的思路也是模仿人类的行为,即人在阅读一些内容时,很多的词(比如一些实体词,地名、人名等)并不能理解,只能进行“死记硬背”,也就是模型中的 pointer 或 copy,在生成每一个 token 时,判断一下是否需要从输入序列中进行 copy,不需要的话直接生成。当然很多工作在解决这个问题时,采用了一种“降维”的思路,即将最小单元从 word 降为 char,尤其对于英语摘要问题,char 的规模比如 word 来说非常小,而中文的效果不会那么明显,因为毕竟汉字的数量也非常多。
▲
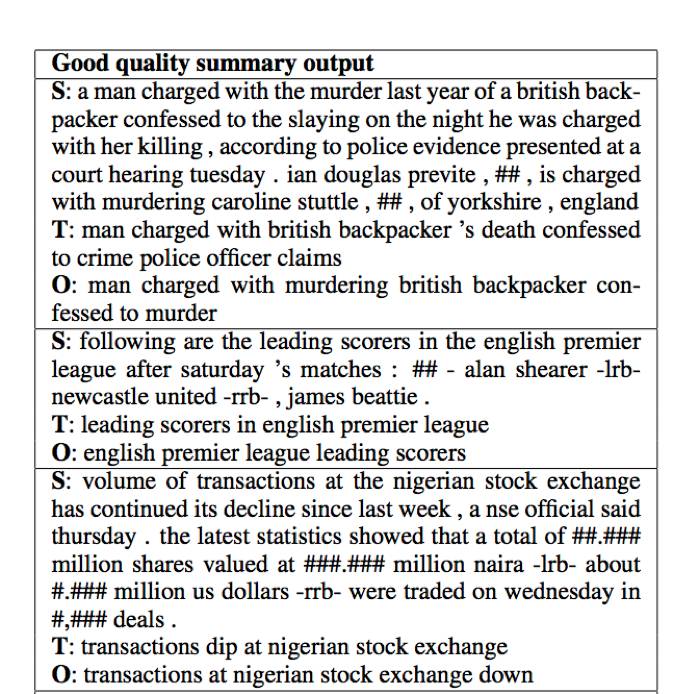
图3:模型生成的摘要结果
上图给出了
「
Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond
」
一文中模型生成的摘要结果,S 为输入序列,即待摘要的内容,T 为目标序列,即给定的摘要内容,O 为输出序列,即算法生成的摘要内容。
利用
Seq2Seq
模型来解决文本摘要问题现在仍然停留在输入序列比较简短的情况,即 sentence-level abstractive summarization 问题,对于 document-level 和 multi document-level 的问题相关工作还很少,而解决这类更加真实的摘要问题,往往还是需要依赖 extractive 的方法,借助深度学习的优势做一些 ranking model。
关于文本摘要这块,去年我写了个系列博客(点击“阅读原文”进行访问),
大家感兴趣的可以读一读,内容都是 2016 年的相关工作。文本摘要在去年火了一阵子然后沉寂了,最近 arXiv 上又不断地更新出一些不错的工作,大家可以关注 PaperWeekly官方微博(@PaperWeekly)和公众号的【每周值得读】栏目,我们会第一时间为大家推荐本周最新的高质量工作。
对话生成
Chatbot 是当前最火的创业领域,是投资的焦点,客观地讲,但真正特别好用的 Chatbot 几乎没有。C 端的 Chatbot 产品比较少,微软小冰算是其中最杰出的代表,小冰的定位并非帮助用户解决什么具体的实际问题,而是情感陪伴,做一个更像人的 bot,从这个角度来看,小冰是非常成功的。做一个有情感的 bot 其实比做一个所谓“有用”(比如:查天气、订机票等)的 bot 更难,上周 PaperWeekly 报道了一篇清华大学计算机系朱小燕、黄民烈老师团队的工作:
PaperWeekly 第35期 | 如何让聊天机器人懂情感
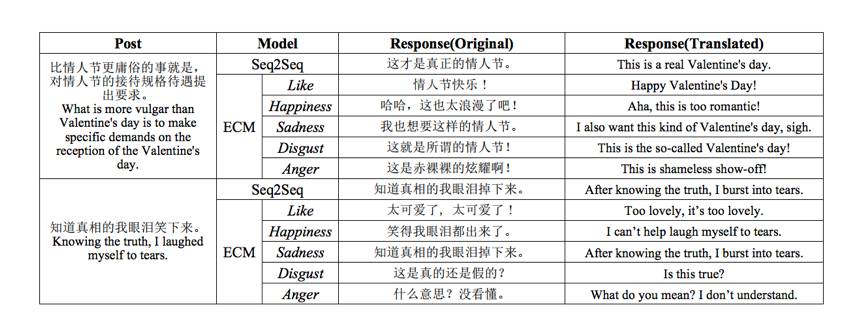
,他们的工作做了一件有趣的事情,给定 context 和情感选项(比如:开心、忧伤等)来生成具有指定情绪的 response,结果可参考下图。
▲
图4:根据情感选项生成对应情绪的回复










