正文
// both("好友")相当于in("好友")和out("好友")的合集
g.V().has("type", A.type).has("id", A.id).both("好友").both("好友").toSet()
前面几个章节,从用户角度介绍了 ByteGraph 的适用场景和对外使用姿势。那 ByteGraph 架构是怎样的,内部是如何工作的呢,这一节就来从内部实现来作进一步介绍。
下面这张图展示了 ByteGraph 的内部架构,其中 bg 是 ByteGraph 的缩写。
就像 MySQL 通常可以分为 SQL 层和引擎层两层一样,ByteGraph 自上而下分为查询层 (bgdb)、存储/事务引擎层(bgkv)、磁盘存储层三层,每层都是由多个进程实例组成。其中 bgdb 层与 bgkv 层混合部署,磁盘存储层独立部署,我们详细介绍每一层的关键设计。
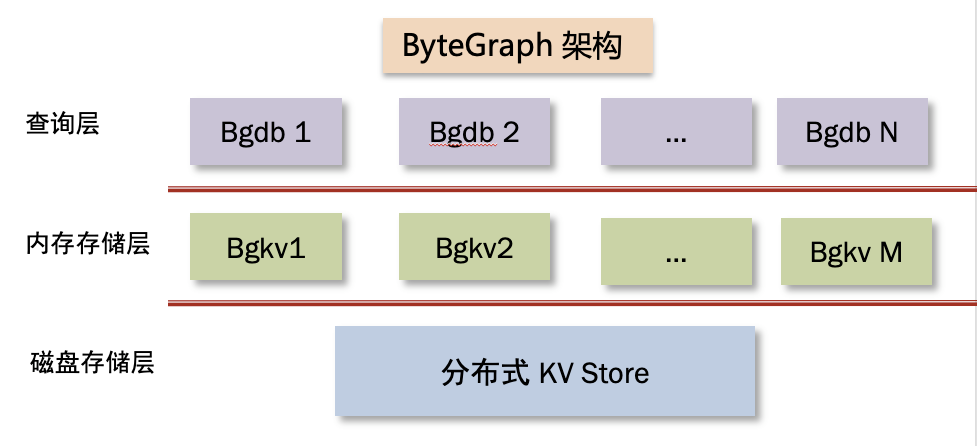
1)查询层(bgdb)
bgdb 层和 MySQL 的 SQL 层一样,主要工作是做读写请求的解析和处理;其中,所谓“处理”可以分为以下三个步骤:
-
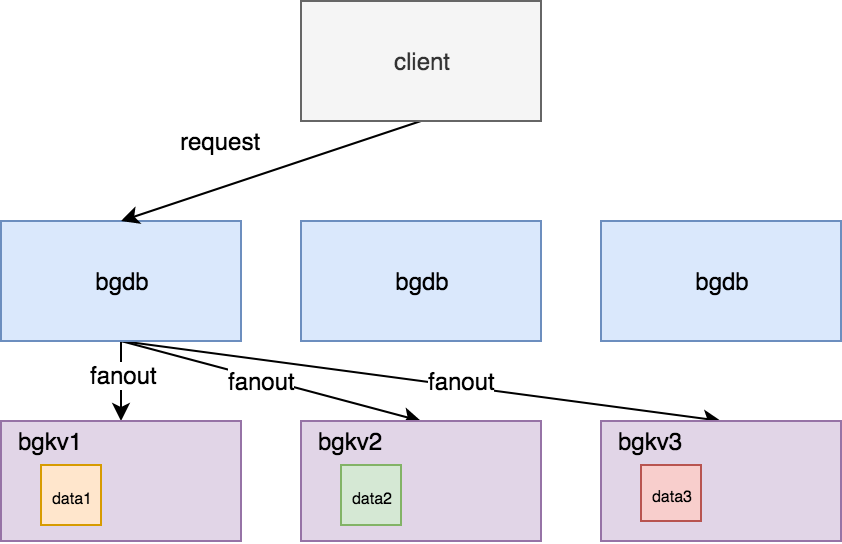
将客户端发来的 Gremlin 查询语句做语法解析,生成执行计划;
-
并根据一定的路由规则(例如一致性哈希)找到目标数据所在的存储节点(bgkv),将执行计划中的读写请求发送给 多个 bgkv;
-
将 bgkv 读写结果汇总以及过滤处理,得到最终结果,返回给客户端。
bgdb 层没有状态,可以水平扩容,用 Go 语言开发。
2)存储/事务引擎层(bgkv)
bgkv 层是由多个进程实例组成,每个实例管理整个集群数据的一个子集(shard / partition)。
bgkv 层的实现和功能有点类似内存数据库,提供高性能的数据读写功能,其特点是:
-
接口不同:只提供点边读写接口;
-
支持算子下推:通过把计算(算子)移动到存储(bgkv)上,能够有效提升读性能;
-
举例:比如某个大 V 最近一年一直在涨粉,bgkv 支持查询最近的 100 个粉丝,则不必读出所有的百万粉丝。
-
缓存存储有机结合:其作为 KV store 的缓存层,提供缓存管理的功能,支持缓存加载、换出、缓存和磁盘同步异步 sync 等复杂功能。
从上述描述可以看出,bgkv 的性能和内存使用效率是非常关键的,因此采用 C++ 编写。
3)磁盘存储层(KV Cluster)
为了能够提供海量存储空间和较高的可靠性、可用性,数据必须最终落入磁盘,我们底层存储是选择了公司自研的分布式 KV store。
4)如何把图存储在 KV 数据库中
上一小节,只是介绍了 ByteGraph 内部三层的关系,细心的读者可能已经发现,ByteGraph 外部是图接口,底层是依赖 KV 存储,那么问题来了:如何把动辄百万粉丝的图数据存储在一个 KV 系统上呢?
在字节跳动的业务场景中,存在很多访问热度和“数据密度”极高的场景,比如抖音的大 V、热门的文章等,其粉丝数或者点赞数会超过千万级别;但作为 KV store,希望业务方的 KV 对的大小(Byte 数)是控制在 KB 量级的,且最好是大小均匀的:对于太大的 value,是会瞬间打满 I/O 路径的,无法保证线上稳定性;对于特别小的 value,则存储效率比较低。事实上,数据大小不均匀这个问题困扰了很多业务团队,在线上也会经常爆出事故。
对于一个有千万粉丝的抖音大 V,相当于图中的某个点有千万条边的出度,不仅要能存储下来,而且要能满足线上毫秒级的增删查改,那么 ByteGraph 是如何解决这个问题的呢?
思路其实很简单,总结来说,就是采用灵活的边聚合方式,使得 KV store 中的 value 大小是均匀的,具体可以用以下四条来描述:
① 一个点(Vertex)和其所有相连的边组成了一数据组(Group);不同的起点和及其终点是属于不同的 Group,是存储在不同的 KV 对的;比如用户 A 的粉丝和用户 B 的粉丝,就是分成不同 KV 存储;
② 对于某一个点的及其出边,当出度数量比较小(KB 级别),将其所有出度即所有终点序列化为一个 KV 对,我们称之为一级存储方式(后面会展开描述);
③ 当一个点的出度逐渐增多,比如一个普通用户逐渐成长为抖音大 V,我们则采用分布式 B-Tree 组织这百万粉丝,我们称之为二级存储;
④ 一级存储和二级存储之间可以在线并发安全的互相切换;
一级存储格式中,只有一个 KV 对,key 和 value 的编码:
二级存储(点的出度大于阈值)
如果一个大 V 疯狂涨粉,则存储粉丝的 value 就会越来越大,解决这个问题的思路也很朴素:拆成多个 KV 对。
但如何拆呢?ByteGraph 的方式就是把所有出度和终点拆成多个 KV 对,所有 KV 对形成一棵逻辑上的分布式 B-Tree,之所以说“逻辑上的”,是因为树中的节点关系是靠 KV 中 key 来指向的,并非内存指针;B-Tree 是分布式的,是指构成这棵树的各级节点是分布在集群多个实例上的,并不是单机索引关系。具体关系如下图所示:

其中,整棵 B-Tree 由多组 KV 对组成,按照关系可以分为三种数据:
-
根节点:根节点本质是一个 KV 系统中的一个 key,其编码方式和一级存储中的 key 相同
-
Meta 数据:
-
Meta 数据本质是一个 KV 中的 value,和根节点组成了 KV 对;
-
Meta 内部存储了多个 PartKey,其中每个 PartKey 都是一个 KV 对中的 key,其对应的 value 数据就是下面介绍的 Part 数据;
-
Part 数据
-
对于二级存储格式,存在多个 Part,每个 Part 存储部分出边的属性和终点 ID
-
每个 Part 都是一个 KV 对的 value,其对应的 key 存储在 Meta 中。
从上述描述可以看出,对于一个出度很多的点和其边的数据(比如大 V 和其粉丝),在 ByteGraph 中,是存储为多个 KV 的,面对增删查改的需求,都需要在 B-Tree 上做二分查找。相比于一条边一个 KV 对或者所有边存储成一个 KV 对的方式,B-Tree 的组织方式能够有效的在读放大和写放大之间做一些动态调整。
但在实际业务场景下,粉丝会处于动态变化之中:新诞生的大 V 会快速新增粉丝,有些大 V 会持续掉粉;因此,存储方式会在一级存储和二级存储之间转换,并且 B-Tree 会持续的分裂或者合并;这就会引发分布式的并发增删查改以及分裂合并等复杂的问题,有机会可以再单独分享下这个有趣的设计。
ByteGraph 和 KV store 的关系,类似文件系统和块设备的关系,块设备负责将存储资源池化并提供 Low Level 的读写接口,文件系统在块设备上把元数据和数据组织成各种树的索引结构,并封装丰富的 POSIX 接口,便于外部使用。
第三节介绍了 ByteGraph 的内在架构,现在我们更进一步,来看看一个分布式存储系统,在面对字节跳动万亿数据上亿并发的业务场景下两个问题的分析。
1)热点数据读写解决
热点数据在字节跳动的线上业务中广泛存在:热点视频、热点文章、大 V 用户、热点广告等等;热点数据可能会出现瞬时出现大量读写。ByteGraph 在线上业务的实践中,打磨出一整套应对性方案。
2)热点读
热点读的场景随处可见,比如线上实际场景:某个热点视频被频繁刷新,查看点赞数量等。在这种场景下,意味着访问有很强的数据局部性,缓存命中率会很高,因此,我们设计实现了多级的 Query Cache 机制以及热点请求转发机制;在 bgdb 查询层缓存查询结果, bgdb 单节点缓存命中读性能 20w QPS 以上,而且多个 bgdb 可以并发处理同一个热点的读请求,则系统整体应对热点度的“弹性”是非常充足的。
3)热点写
热点读和热点写通常是相伴而生的,热点写的例子也是随处可见,比如:热点新闻被疯狂转发, 热点视频被疯狂点赞等等。对于数据库而言,热点写入导致的性能退化的背后原因通常有两个:行锁冲突高或者磁盘写入 IOPS 被打满,我们分别来分析:
① 行锁冲突高:目前 ByteGraph 是单行事务模型,只有内存结构锁,这个锁的并发量是每秒千万级,基本不会构成写入瓶颈;
② 磁盘 IOPS 被打满:
-
IOPS(I/O Count Per Second)的概念:磁盘每秒的写入请求数量是有上限的,不同型号的固态硬盘的 IOPS 各异,但都有一个上限,当上游写入流量超过这个阈值时候,请求就会排队,造成整个数据通路堵塞,延迟就会呈现指数上涨最终服务变成不可用。
-
Group Commit 解决方案:Group Commit 是数据库中的一个成熟的技术方案,简单来讲,就是多个写请求在 bgkv 内存中汇聚起来,聚成一个 Batch 写入 KV store,则对外体现的写入速率就是 BatchSize * IOPS。








