正文
Kubernetes by example (http://kubernetesbyexample.com/)
Kubernetes basics - interactive tutorial (https://kubernetes.io/docs/tutorials/kubernetes-basics/)
集群结构的概览
主要思想:即用一个小 CPU 作为主控节点(master node)来控制一个集群的 GPU-工作节点(GPU-worker nodes)。
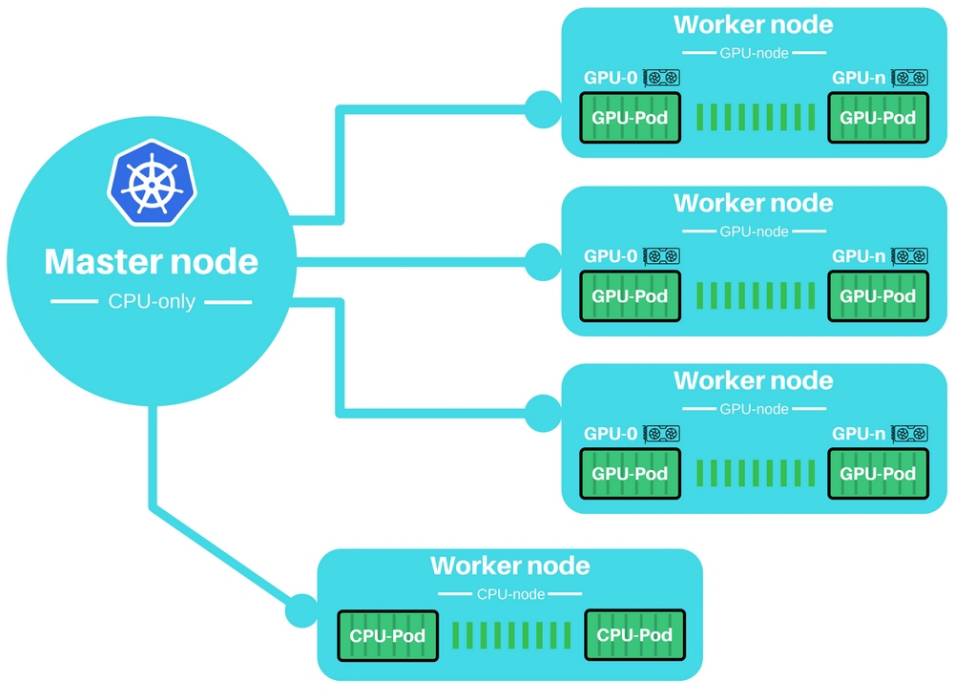
初始化节点
在我们使用集群之前,先对集群进行初始化是很重要的。因此每个节点必须被手动初始化,然后才能加入到集群当中。
我的配置
此配置对上述案例十分适用——对其他实例或操作系统来说,往往需要一些额外的调试。
Master 主控节点
-
SSH 访问
-
ufw 停用
-
启用端口(udp 和 tcp)
Worker 工作站
-
SSH 访问
-
ufw 停用
-
启用端口(udp 和 tcp)
关于安全性:在使用过程中你应该关闭一些防火墙——为了更加简单,应该禁用 ufw。为实际的生产工作负载设置 Kubernetes 当然应该包括启用一些防火墙,像 ufw, iptables 或你的云端服务器的防火墙。也要注意在云端设置一个工作集群可能更加复杂。你的云端供应商通常会提供一个他们自己的防火墙,这是和主机防火墙相分离的。你可能必须要停用 ufw,并且也要启用云端供应商的防火墙,使本教程的步骤可以正常进行下去。
设置向导
这些说明涵盖了我们在 Ubuntu 16.04 系统上的操作经验,可能有些地方并不适合于转移到其他操作平台。
如下所示,我们构建了两个脚本,它们能完全启动主控节点(master node)和工作节点(worker node)。如果你希望快速运行,那么就只需要使用以下两个脚本就行。否则的话,我建议跟着设置向导一步步阅读。
快速通道—设置脚本
下面我们将利用脚本进行快速设定。首先需要复制对应的脚本到主节点和工作节点的机器上:
主控节点
执行上面的主控节点初始化脚本,并记下代号。代号通常看起来像:--token f38242.e7f3XXXXXXXXe231e
chmod +x init-master.sh
sudo ./init-master.sh
工作节点
执行上面的工作节点初始化脚本,并要求输入正确的主控节点代号和 IP,端口通常使用 6443。
chmod +x init-worker.sh
sudo ./init-worker.sh
:
详细的安装说明
主控节点
1. 添加 Kubernetes 资源库到软件包管理器中:
sudo bash -c 'apt-get update && apt-get install -y apt-transport-https
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <
/etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
apt-get update'
2. 安装 docker-engine、kubeadm、kubectl 和 kubernetes-cni 库
sudo apt-get install -y docker-engine
sudo apt-get install -y kubelet kubeadm kubectl kubernetes-cni
sudo groupadd docker
sudo usermod -aG docker $USER
echo 'You might need to reboot / relogin to make docker work correctly'
3. 因为我们希望使用 GPU 构建一个计算机集群,所以我们需要 GPU 能在主控节点中进行加速。当然,也许该说明会因为新版本的 Kubernetes 出现而需要更改。
3.1 将 GPU 支持添加到 Kubeadm 配置中,这个时候集群是没有初始化的。这一步需要在集群每一个节点的机器中完成,即使有一些没有 GPU。
sudo vim /etc/systemd/system/kubelet.service.d/<
>-kubeadm.conf
因此,添加 flag --feature-gates="Accelerators=true" 到 ExecStart 中,命令行大概如下所示:





