正文
因为训练过程涉及到巨大的数据集的模型,机器学习平台往往是分布式的,它们往往会使用并行的几十个或几百个工作器(worker)来训练模型。据估计,在不久的将来,数据中心中运行的绝大多数任务都将会是机器学习任务。
我有分布式系统的研究背景,所以我们决定从分布式系统的角度研究这些机器学习平台并分析其通信和控制局限。我们也调查了这些平台的容错能力和编程难度。
我们将这些分布式机器学习平台归类为了三大基本设计方法:
1. 基本数据流(basic dataflow)
2. 参数服务器模型(parameter-server model)
3. 先进数据流(advanced dataflow)
我们对这三种方法进行了简要介绍并举例进行了说明,其中基本数据流方法使用了 Apache Spark、参数服务器模型使用了 PMLS(Petuum)、先进数据流模型使用了 TensorFlow 和 MXNet。我们提供了几个比较性能的评估结果。论文里还有更多评估结果。不幸的是,作为学术界的一个小团队,我们无法进行大规模的评估。
在本文末尾,我给出了对分布式机器学习平台未来研究工作的总结和建议。如果你已经了解这些分布式机器学习平台,可以直接跳至末尾查看结论。
Spark
在 Spark 中,计算被建模成有向无环图(DAG:directed acyclic graph),其中每一个顶点都代表一个弹性分布式数据集(RDD:Resilient Distributed Dataset),每一条边都代表对 RDD 的一个运算。RDD 是被分到了不同逻辑分区的对象的集合,这些逻辑分区是作为 in-memory 存储和处理的,带有到磁盘的 shuffle/overflow。
在一个 DAG 中,从顶点 A 到顶点 B 的边 E 表示:RDD B 是在 RDD A 上执行运算 E 后得到的结果。运算有两种:变换(transformation)和动作(action)。变换(比如:映射、过滤、连接)是指在一个 RDD 上执行一种运算生成一个新的 RDD。
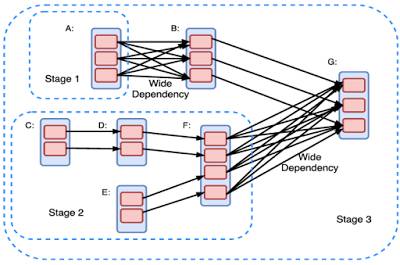
Spark 用户需要将计算建模为 DAG,从而在 RDD 上进行变换或运行动作。DAG 需要被编译为 stage。每个 stage 作为一系列并行运行的任务执行(每个分区执行一个任务)。简单狭窄的依赖关系有利于高效执行,而宽广的依赖关系会引入瓶颈,因为它们会扰乱流程,而且需要通信密集的 shuffle 运算。
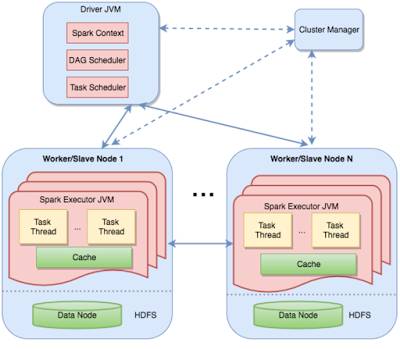
Spark 中的分布式执行是通过将这种 DAG stage 分割到不同的机器上执行的。这张图清晰地显示了这种 master-worker 架构。驱动器(driver)包含了任务和两个调度器(scheduler)组件——DAG 调度器和任务调度器;并且还要将任务对应到工作器。
Spark 是为一般的数据处理设计的,并不特定于机器学习。但是使用 MLlib for Spark,也可以在 Spark 上进行机器学习。在基本的设置中,Spark 将模型参数存储在驱动器节点,工作器与驱动器通信从而在每次迭代后更新这些参数。对于大规模部署而言,这些模型参数可能并不适合驱动器,并且会作为一个 RDD 而进行维护更新。这会带来大量额外开销,因为每次迭代都需要创造一个新的 RDD 来保存更新后的模型参数。更新模型涉及到在整个机器/磁盘上重排数据,这就限制了 Spark 的扩展性。这是 Spark 的基本数据流模型(DAG)的不足之处。Spark 并不能很好地支持机器学习所需的迭代。










