正文
这是我们在APP SDK返回的原始数据的示意,这个SDK Android有一个版本,IOS有一个版本。在事件被触发的时候被返回的。传统的统计实际上只有启动跟退出才可以收集数据,现在用户可以自定义事件,定义的事件就被触发后,相关的数据传回来了。
这里面的数据样本显示出的信息有很多,我细讲下。每个APP会有一个
ID
,是帮我们决定是哪个APP的,后面【友盟+】会有ID,这是【友盟+】自己来判断这个设备是哪个设备的,后面有
imei
,这个是Android上一个标准的设备标识符,是国际标准设备标识符,后面是
mac
地址。然后
utdid
,这个是阿里的一个ID,因为我们属于阿里集团,后面包括这是什么版本,比如这个是Android4.3的版本,这个APP本身是什么版本。再后面是一些
sessions
信息,就是说你这一段行为能够拿到什么数据,如果你定义比较复杂的事件这些事件的信息也会出来,这个是APP端。

WEB端,我们是JS的SDK,通过http或者https协议传数,这个
Referer
告诉你这个访问是从百度来的,到了友盟+这个网站,包括你的屏幕的维度,你用的语言,包括我们自己ID。
useragent
是告诉你这个浏览器是什么样的。在无线端我们是通过设备ID做唯一判断的。
在网站端我们最开始判断的不是一个设备,而是一个浏览器,
比如说你在PC上开了IE、Chrome、360,这对于我们来说可能是三个ID,但会有一些算法把这几个ID连起来,告诉你这可能是同一个电脑的,或者同一个人的,我们会有一些算法把它们打通。
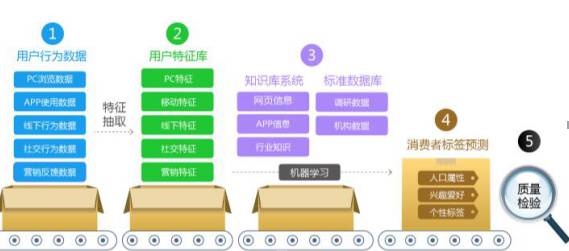
原始数据需要深层的加工处理,做一些基础的分析
,第一步是用户行为数据,第二步是通过行为数据做特征提取,第三步会有一些知识体系、数据库,通过机器学习算法给消费者或者设备打上标签,这个标签是往后所有应用的基础数据,以后再使用就用第四步数据就好了,前面的这些做一次性处理就差不多了,第三步机器学习的模型我们会不断更新,来做更好的标签的生产。
标签会从各个维度判断这个设备背后的人
,第一类属于基础属性,我们要判断性别、年龄、消费水平,而这些判断都是基于模型,我们需要收集一些训练数据,有了这些训练数据以后,比如说性别,我们就会看男的跟女的在用APP行为上,在浏览网站行为上有什么不同,这实际上是一个二分类模型判断性别。像年龄段,这是一个多分类模型判断属于哪个年龄段。
下面要重点谈下训练模型这件事。
性别比较好说,要么是男要么是女,预测年龄虽然是一个多分类模型,但是在工业界里面很多场景里面大家用得更多是二分类,每一个年龄段做一个模型。但是二分类有一个问题,人不可能同时处于两个年龄段,所以就涉及到一个二分类模型结果的比较问题。现在很少有模型输出的是正确的概率,这意味着我做了两个模型,这两个模型的分数是不可比的。
比如说我做一个模型说我判断这个是一个桌子,另外一个模型判断说这是一个柜子,桌子模型说这个是桌子的可能性是0.6,柜子的模型说可能性是0.9,那么你说这就是个柜子吗?你不能这么说,因为0.9折换到概率以后可能比0.6的概率还要低,概率为什么会不同?第一,我们训练模型往往用得不是原始数据的比例,尤其是对于小的类目,对于小的类目来说,如果做一个随机采样做一个模型的话,有可能它的正样本特别少,我可能从它本身拿样本里的全量,剩下的可能拿出10%,这个的话模型看见的事实是,这个小类可能在我整体里面占了20%,不是它的可能占了80%,实际上真实世界这类可能只占2%,剩下的是98%,所以你这个模型做得再准也不可能得到正确的probability,没有正确的probability两个二分类模型是没法比的。
那么
这个怎么解决呢
?有比较粗暴的办法,就像一些兴趣标签,比如说兴趣偏好,一个人有多个兴趣没关系,一般出来一个模型只要这个分大于0.5就认为他对于这个有兴趣,那就好了,但是对于年龄段来说就没法这么做。这个你要怎么做呢?我们叫分数的校准,我拿出一些独立的数据,我用我的模型打一下分,我可以算出每一个分数段它实际的概率是多少,比如我算出0.9的时候,所有低于0.9的样本里面可能有10%真是这个样本,0.9就对应了概率是0.1,所以我们做了这个映射以后这个两个模型才有可比性。
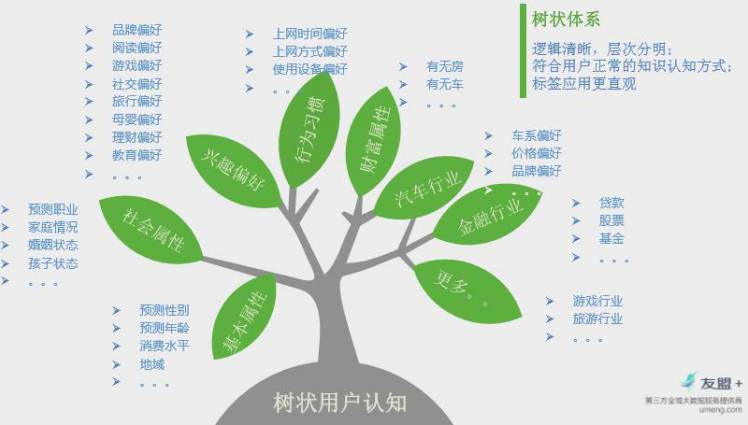
这是我们树状的用户认知体系
,这里面分了几个大类,基本属性、社会属性、兴趣偏好、行为习惯、财富、汽车行业、金融行业、其他,这是一种方法,
是固定的标签体系
。但是现在很多时候我们用的叫场景标签,Google把人的一天24小时定义了60个场景,比如说,你刚刚起床的场景是怎样的,你一打开电视的场景是怎样的,需要判断的是你在这个场景情况下最容易被什么样的广告打动。现在的标签体系有很多自定义的或者说基于场景或需求的,所以我们现在做得一个
很重要的工作是把标签的生产自动化
,如果客户提给我们一个需求,我们可以根据你的需求迅速自动产生一个模型,这个模型能够输出标签。
关于标签的生成方法,第一种标签的生成方法叫基于事实的
,我们在实际应用中经常用到。我给你一批客户,你告诉我里面哪些人过去一个月开启的这类APP十次,他只要知道这个,基于事实的好处是,它有事实在所以特别容易解释清楚。不好的一点是,它的reach比较小,所谓reach就是说我有多少人能够有这样的标签,按体育APP来说,同样200人,可能有50人最近两天开启了10次以上的体育APP,如果广告主要这个,给我一万块钱,我说这一万块钱只能投给这50人,你要想再投100人我没法投了,因为没有了。
但是如果是模型预测就没有问题了
,模型预测每个人都有对于体育兴趣的分,那就是根据你要的精准性,你说我要很精准,200人给你排名,排在第一的我认为是对体育最有兴趣的,排在最后的一个我认为是这200个人里最没兴趣的,但是他可能还是有一些兴趣的,
对于广告主来说他愿意触达多少人就能触达多少人
,只不过他要理解我的广度跟我的精准性的关系就好了。因为我们在兴趣后面会加一个分数,就是置信度,置信度广告主可以选,需要什么样的置信度。

下面
我要重点讲下“打通”的问题,首先让我们了解下数据打通的方法。
比如说体育类APP,我怎么知道这是个体育类APP?开发者当时整合SDK的时候,我们并没有方法验证你填得APP类别是不是你真正的APP类别,所以我们需要有一个模型通过APP的描述对APP做另外一个层次的判断,这个基本上就是一个自然语言处理的方式。
PC的相对来说复杂一点,第一个我们的数据量比较多,PC一旦知道你的URL的话我可以去爬,可以把你的网站都爬下来,可以用比较复杂的模型来做,但是
实现的时候也会用一些基于事实类的方法
。比如说第一个是规则,
我只要看它的URL规则就知道它是哪类的
,这一类把规则梳理一遍,就可以去判断。
第二个是用模型去判断,通过标题、正文等建一个模型做判断
,这个要求比较高,打分大于0.9的我们才认为它是这一类的。
第三个是映射
,我们会对前面没有匹配的按照用户自填的做一个映射。当然我们还有
LDA模型
会把每一篇的文章做成Topic去做下一个子目录的类别,这些小类可能是有一个LDA打标签,再去引申到后面使用者身上的兴趣标签。










