正文
完成了前面的搜索之后,如果你愿意发单的话,那下一步就是派单。我们每两秒钟会接到大量需求,我们也知道这两秒之内有多少运力,有多少空车是可以接单的,有些载人车也是可以接的,如果它是拼车单的话。派单是滴滴最核心的一个模块。
刚才讲到,每两秒钟我们就积累了一大批乘客,以及一大批司机,然后做最优的匹配,每个乘客我们会匹配最优的一个司机。那怎么做匹配?我这里讲的大部分是快车,会稍微讲一下顺风车,因为它们的匹配场景不一样。
我们分单有一个历史过程,最早期是抢单,就是我们把每个司机周围的订单都拨给他,所以司机会看到十几个订单,然后司机要选。后来发现这个效率不高。所以从15年我们开始做智能派单。
大部分情况下我们希望找的是最理想的一个乘客,所以就指派了,那这样的话就是一对一的匹配,之前是一对多的。那这样我们matching的精度就更重要了。
这里面就有一个匹配度的问题,就是这个乘客和这个司机匹配度高还是低。最早期的时候滴滴用的是直线距离,因为当时的很多基础功能还不完善。后来我们应该用路面距离,司机实际开过来的距离应该作为一个匹配度。所以从15年开始,路径规划比较完善了,我们就开始用路面距离。我们会先预估出来哪一条路径是最合理的,然后让司机去接乘客。但这个其实还不是最合理的,最合理的应该是时间,比如同样的两公里有情况一和情况二两种选择,比如情况二需要十分钟,情况一的距离可能是类似的,但是时间可能只需要五分钟,因为它的路况更好。最合理的应该是用时间来衡量。

派单里面我们讲到怎么去评估两个匹配的好坏,需要两个核心的算法,一个是路径规划,另外一个是ETA。
说一下分单的挑战。我刚才讲了,我们跟传统的搜索不一样,我们是实时的搜索,每两秒钟做预测,这里牵涉到非常多的地图的应用,比如说路径规划,ETA。因为其实我们不知道哪个司机离你最近,所以我们一般是找到你周围的所有的司机来做匹配,然后做路径规划和ETA。而且这是非拼车的方式,如果你是拼车单,那你们俩还要做匹配,复杂度就成了N的平方。所以这个复杂度特别高,而且要保证实时实施。
刚才我讲到,ETA是滴滴非常重要的一个功能,在预估价、分单等方面都有应用。比如说你从A到B,假设已经知道路径了,应该怎么算时间?我们把它看成一个机器学习问题,label很简单,就是时间。那这里最核心的特征怎么挖掘?这里有一大堆的路网特征,实时路况特征,历史特征,等等。我们从最早期的七八十个特征到最后有几千万的特征,这个特征量越来越大,效果的话是越来越好。误差的话,从15年开始,到我们去年完成大规模的稀疏的模型,误差明显降低。
这里面有几点,一个是数据量越来越大,同样的模型数据量越来越大,自然精度会提高。第二,我们的模型也是越来越智能了。比如最近我们用了深度学习模型来预估时间。
大家都知道深度学习在很多领域已经有非常成功的应用了,比如说在图像、文本、speech等方向。在交通方面其实还很少,所以大家如果对在深度学习探索新的应用感兴趣的话,我觉得交通是比较有潜力的,因为现在工作还非常少。但是深度学习在交通的数据还是非常有前景的。
深度学习我们现在刚刚上线不久,效果还是不错的,一上去模型的精度就完全比之前好了。它的好处是它还有很大的提高空间,数据越大,它的威力越大。我认为这肯定是一个大的趋势。
有了时间和距离之后,这里每一列是一个用户,每一行是一个司机,分别是不同类型的订单,有快车,专车,等等。每个车跟每个订单都有一个匹配度,比如说时间和距离,比如说时间越短的话,匹配度应该越好。这样得到一个大的矩阵,然后做订单的分配,得到最佳匹配。这个已经有很多年的研究,有最优解。
但是更有效的分单还需要考虑未来,找到未来一段时间收益最大化的最优解。最近我们上线了一套算法,用了增强学习。这个就涉及到供需预测,你需要知道比如说在未来半个小时,北京所有的区域大概有多少订单,哪个区域订单比较多,等等。这个就需要供需预测,这个对我们来说是非常重要的事情。去年滴滴举办了第一届算法大赛,主题就是供需预测,预测每一个区域大概会有多少个需求,多少个司机。我们现在的预测精度达到85%。

下面讲一下供需的不平衡。很多情况下打不到车的问题是供需不平衡。图中绿色表示这些区域车的空闲运力比较多,红色区域表示车比较少。怎么解决这个问题?我们第一个方法是做预测,刚才讲过了,我们如果能提前预测,比如说未来半个小时各个地方供需的情况,如果能预测到这个区域缺10辆车,我们提前把它调过去,这是最理想的。
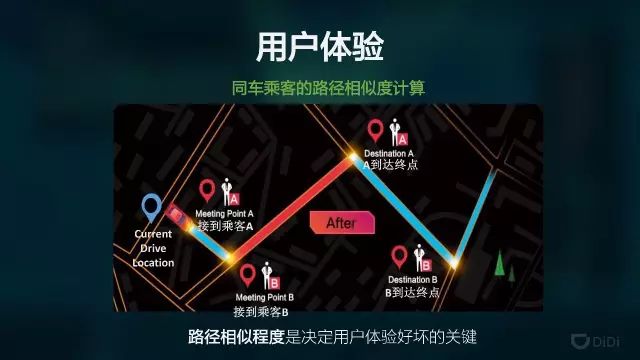
这里面核心的问题是如何保证乘客的体验。
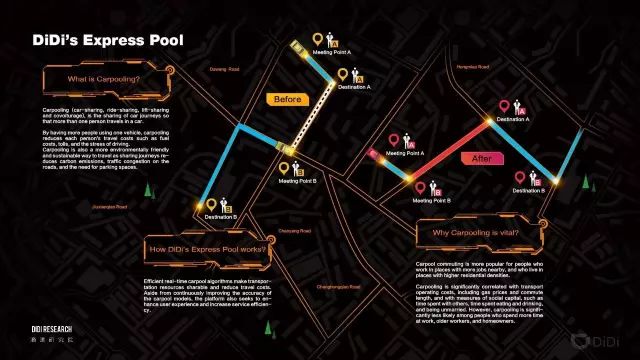
这里我们建立一个机器学习模型,根据历史上发生的大量的拼车单,分析哪一些是乘客投诉说体验很差的,哪一些是大家说好的,然后我们找出特征来。我们需要找出一些重要的特征,能够刻画这个体验。比如说这两单拼成了,我们大概能预测一下这个体验好还是坏,如果预估体验不好的话,我们就不让他们拼车成功。这背后其实是路径规划,相似性,以及体验的预测。









