正文

然而,在加入OpenAI、担任两年研究员后,他的想法开始转变。

在那里,他被分配的任务是为GPT-4收集互联网数据,这个神经网络花了几个月的时间,分析了互联网上几乎所有英语文本。
Balaji认为,这种做法违反了美国关于已发表作品的「合理使用」法律。今年10月底,他在个人网站上发布一篇文章,论证了这一观点。
目前没有任何已知因素,能够支持「ChatGPT对其训练数据的使用是合理的」。但需要说明的是,这些论点并非仅针对ChatGPT,类似的论述也适用于各个领域的众多生成式AI产品。

根据《纽约时报》律师的说法,Balaji掌握着「独特的相关文件」,在纽约时报对OpenAI的诉讼中,这些文件极为有利。
在准备取证前,纽约时报提到,至少12人(多为OpenAI的前任或现任员工)掌握着对案件有帮助的材料。
在过去一年中,OpenAI的估值已经翻了一倍,但新闻机构认为,该公司和微软抄袭和盗用了自己的文章,严重损害了它们的商业模式。
诉讼书指出——
微软和OpenAI轻易地攫取了记者、新闻工作者、评论员、编辑等为地方报纸作出贡献的劳动成果——完全无视这些为地方社区提供新闻的创作者和发布者的付出,更遑论他们的法律权利。
而对于这些指控,OpenAI予以坚决否认。他们强调,大模型训练中的所有工作,都符合「合理使用」法律规定。
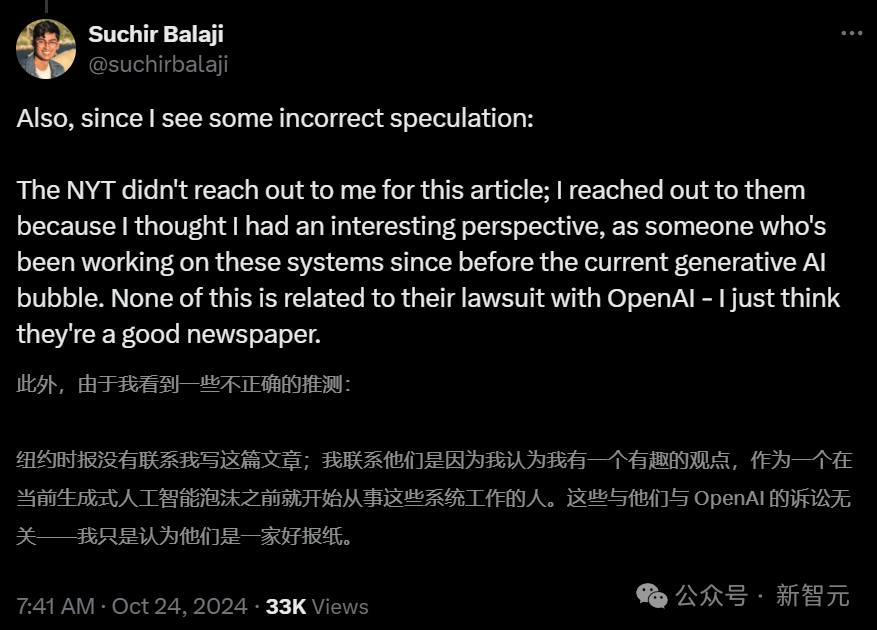
为什么OpenAI违反了「合理使用」法?Balaji在长篇博文中,列出了详尽的分析。
他引用了1976年《版权法》第107条中对「合理使用」的定义。
是否符合「合理使用」,应考虑的因素包括以下四条:
(1)使用的目的和性质,包括该使用是否具有商业性质或是否用于非营利教育目的;
(2)受版权保护作品的性质;
(3)所使用部分相对于整个受版权保护作品的数量和实质性;
(4)该使用对受版权保护作品的潜在市场或价值的影响。
按(4)、(1)、(2)、(3)的顺序,Balaji做了详细论证。
因素(4):对受版权保护作品的潜在市场影响
由于ChatGPT训练集对市场价值的影响,会因数据来源而异,而且由于其训练集并未公开,这个问题无法直接回答。
不过,某些研究可以量化这个结果。
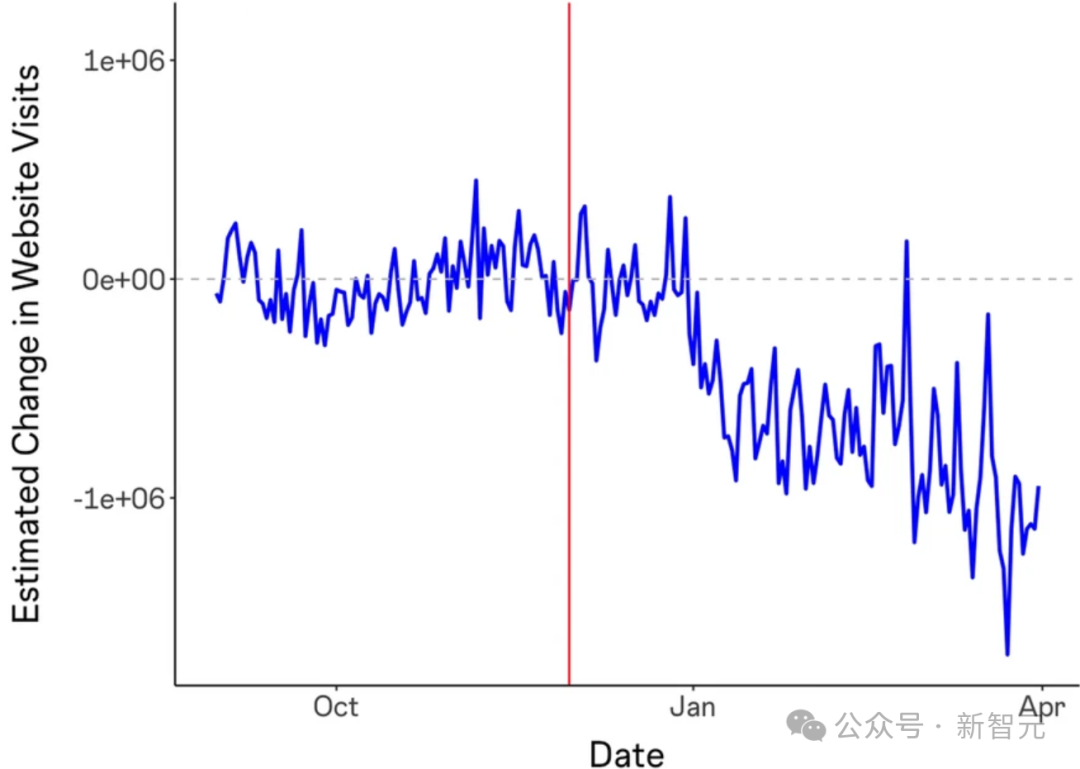
《生成式AI对在线知识社区的影响》发现,在ChatGPT发布后,Stack Overflow的访问量下降了约12%。
此外,ChatGPT发布后每个主题的提问数量也有所下降。
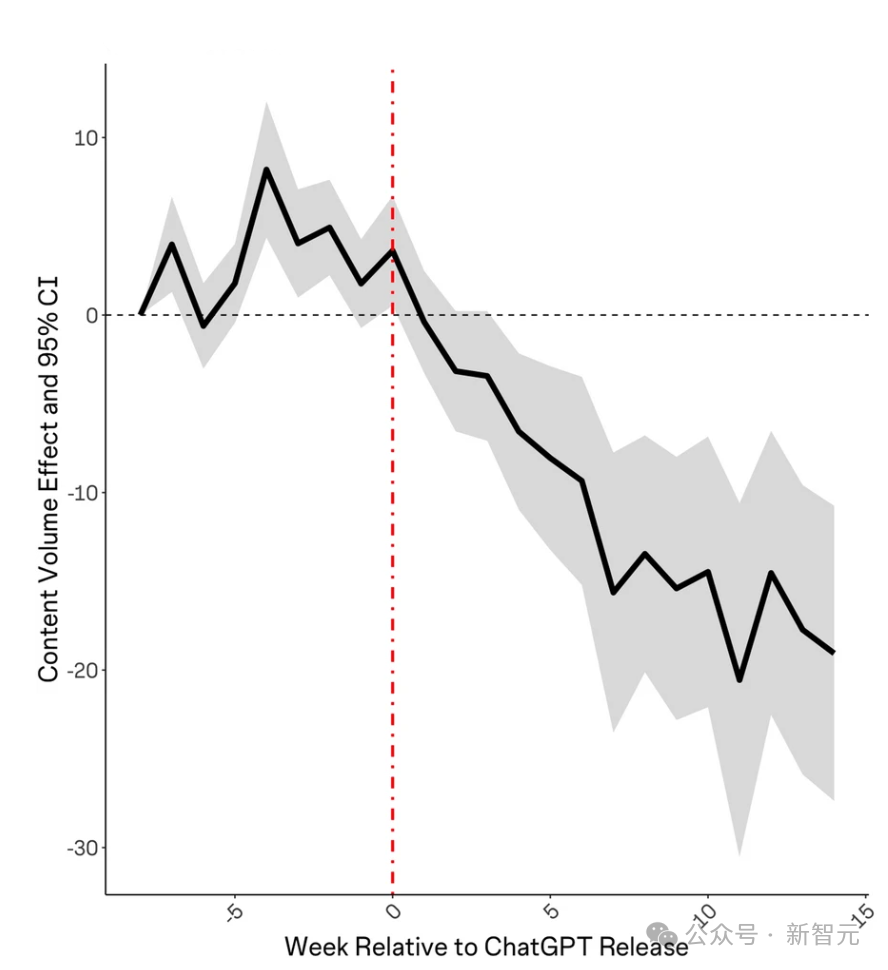
提问者的平均账户年龄也在ChatGPT发布后呈上升趋势,这表明新成员要么没有加入,要么正在离开社区。

而Stack Overflow,显然不是唯一受ChatGPT影响的网站。例如,作业帮助网站Chegg在报告ChatGPT影响其增长后,股价下跌了40%。








