正文
各国对人工智能的动作
最近有很多不同的基金或者国家面向人工智能或者深度学习方面都有不同的动作。
比如说美国的国家科学基金会(NSF)从今年开始对于机器学习原创工作仍然大力支持,但是对于简单使用深度学习去解决问题的研究已经不再支持了。所以前段时间我去美国开会,马里兰大学的一位很知名的搞人工智能的专家就调侃说,现在都在说Deep Learing,Deep YES,Learning NO。
因为它的学习严格的说不是学习,而是训练,是用大数据在训练一个结构,而不是真的知道知识是什么,这可能只是一个动作。
国内的自然科学基金业也在采取一些动作,包括我们会把和人工智能相关的一些研究列入支持。比如我们将会把智能科学单独作为一个学科代码,将来在整个自然科学申请体系里面列进去,每一个学科代码在我们这里相当于是一个处的编制。
有的同事知道我另外一个身份是国家自然科学基金委员会的副主任,我现在分管信息学部,自然科学基金今年248亿预算,8个学部,有的学部大一点,有的学部小一点。信息学部今年的预算是1/8左右,也就是说28-29亿,现在四个处在分,每个处是不到5亿。如果我多了一个信息科学代码,那它就会从1/4变成1/5,所以大家可以知道我们将来对信息科学的支持力度会有多大。

当然没有申请人也不会给钱,因为自然科学基金是竞争性的,没有竞争就拿不到钱。所谓竞争,大概就是1/4,大概就是25-30%之间的申请率,平均3份以上选择1份来支持。这是一个信号,我国今后会对人工智能或者机器人的研究会有比较大的资源注入进去。
●
●
●
人工智能的划分
对于未来来说,现在的人工智能和未来的人工智能到底阶段上怎么来划分?或者说我们现在做了多少事,未来还有多少事需要做?
不要认为我们解决了人工智能的所有问题,我们解决的问题还是很小一部分。是哪一部分呢?我们把这个矩阵做成四部分来看。
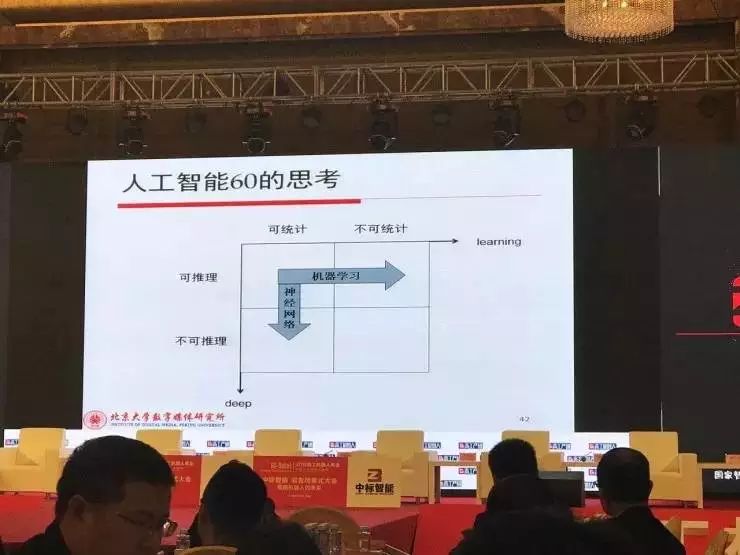
左上角部分叫做可统计、可推理的知识,或者可统计、可推理的世界。什么叫可统计?只要数据多了,一统计就找到规律了。什么是可推理?它的因果关系能归纳出来。当然这个可推理既是可能是基于大数据的推理,也可能是基于符号的推理。现在它可以用了,因为有了深度学习,我们又有了前些年的逻辑演算的基本算法,这是可以做的。
这一部分工业界可以用了,拿去做机器人、去做各种各样的知识决策系统都是可以的。
还有另外三部分,包括不可统计可推理。什么东西是这样的?要么数据不完备,要么数据里面特征的描述还没有找到更好的办法,可能里面是很稀疏的东西,表达根本没有办法统计出来,在里面是游离状态,但是是可推理的,可以写出正确的规则。这些靠大数据解决不了问题,但是只能靠传统的逻辑来做。这方面又相当脆弱,许多东西需要进一步去验证。










