正文
除了进行短时间微观的天气、灾害预测之外,还可以进行更加长期和宏观的环境和生态变迁预测。森林和农田面积缩小、野生动物植物濒危、海岸线上升,温室效应这些问题是地球面临的“慢性问题“。如果人类知道越多地球生态系统以及天气形态变化数据,就越容易模型化未来环境的变迁,进而阻止不好的转变发生。而大数据帮助人类收集、储存和挖掘更多的地球数据,同时还提供了预测的工具。
基于用户和车辆的LBS定位数据,分析人车出行的个体和群体特征,进行交通行为的预测。交通部门可预测不同时点不同道路的车流量进行智能的车辆调度,或应用潮汐车道;用户则可以根据预测结果选择拥堵几率更低的道路。
百度基于地图应用的LBS预测涵盖范围更广。春运期间预测人们的迁徙趋势指导火车线路和航线的设置,节假日预测景点的人流量指导人们的景区选择,平时还有百度热力图来告诉用户城市商圈、动物园等地点的人流情况,指导用户出行选择和商家的选点选址。
多尔戈夫的团队利用机器学习算法来创造路上行人的模型。无人驾驶汽车行驶的每一英里路程的情况都会被记录下来,汽车电脑就会保持这些数据,并分析各种不同的对象在不同的环境中如何表现。有些司机的行为可能会被设置为固定变量(如“绿灯亮,汽车行”),但是汽车电脑不会死搬硬套这种逻辑,而是从实际的司机行为中进行学习。
这样一来,跟在一辆垃圾运输卡车后面行驶的汽车,如果卡车停止行进,那么汽车可能会选择变道绕过去,而不是也跟着停下来。谷歌已建立了70万英里的行驶数据,这有助于谷歌汽车根据自己的学习经验来调整自己的行为。
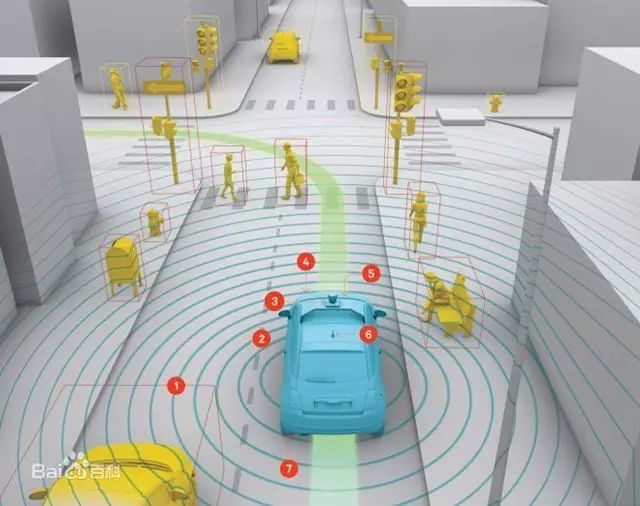
http://www.5lian.cn/html/2014/chelianwang_0522/42125_4.html
加州电网系统运营中心管理着加州超过80%的电网,向3500万用户每年输送2.89亿兆瓦电力,电力线长度超过25000英里。该中心采用了Space-Time Insight的软件进行智能管理,综合分析来自包括天气、传感器、计量设备等各种数据源的海量数据,预测各地的能源需求变化,进行智能电能调度,平衡全网的电力供应和需求,并对潜在危机做出快速响应。中国智能电网业已在尝试类似大数据预测应用。
>>>>
按照数据分析的实时性,分为实时数据分析和离线数据分析两种。
实时数据分析一般用于金融、移动和互联网B2C等产品,往往要求在数秒内返回上亿行数据的分析,从而达到不影响用户体验的目的。要满足这样的需求,可以采用精心设计的传统关系型数据库组成并行处理集群,或者采用一些内存计算平台,或者采用HDD的架构,这些无疑都需要比较高的软硬件成本。目前比较新的海量数据实时分析工具有EMC的Greenplum、SAP的HANA等。
对于大多数反馈时间要求不是那么严苛的应用,比如离线统计分析、机器学习、搜索引擎的反向索引计算、推荐引擎的计算等,应采用离线分析的方式,通过数据采集工具将日志数据导入专用的分析平台。但面对海量数据,传统的ETL工具往往彻底失效,主要原因是数据格式转换的开销太大,在性能上无法满足海量数据的采集需求。互联网企业的海量数据采集工具,有Facebook开源的Scribe、LinkedIn开源的Kafka、淘宝开源的Timetunnel、Hadoop的Chukwa等,均可以满足每秒数百MB的日志数据采集和传输需求,并将这些数据上载到Hadoop中央系统上。
>>>>
按照大数据的数据量,分为内存级别、BI级别、海量级别三种。
这里的内存级别指的是数据量不超过集群的内存最大值。不要小看今天内存的容量,Facebook缓存在内存的Memcached中的数据高达320TB,而目前的PC服务器,内存也可以超过百GB。因此可以采用一些内存数据库,将热点数据常驻内存之中,从而取得非常快速的分析能力,非常适合实时分析业务。图1是一种实际可行的MongoDB分析架构。
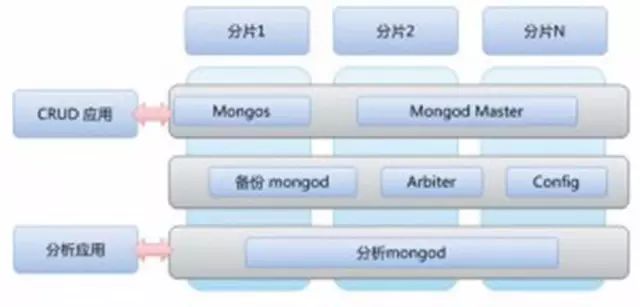
图1 用于实时分析的MongoDB架构
MongoDB大集群目前存在一些稳定性问题,会发生周期性的写堵塞和主从同步失效,但仍不失为一种潜力十足的可以用于高速数据分析的NoSQL。
此外,目前大多数服务厂商都已经推出了带4GB以上SSD的解决方案,利用内存+SSD,也可以轻易达到内存分析的性能。随着SSD的发展,内存数据分析必然能得到更加广泛的应用。
BI级别指的是那些对于内存来说太大的数据量,但一般可以将其放入传统的BI产品和专门设计的BI数据库之中进行分析。目前主流的BI产品都有支持TB级以上的数据分析方案。种类繁多。
海量级别指的是对于数据库和BI产品已经完全失效或者成本过高的数据量。海量数据级别的优秀企业级产品也有很多,但基于软硬件的成本原因,目前大多数互联网企业采用Hadoop的HDFS分布式文件系统来存储数据,并使用MapReduce进行分析。本文稍后将主要介绍Hadoop上基于MapReduce的一个多维数据分析平台。
大数据的采集是指利用多个数据库来接收发自客户端(Web、App或者传感器形式等)的 数据,并且用户可以通过这些数据库来进行简单的查询和处理工作。比如,电商会使用传统的关系型数据库MySQL和Oracle等来存储每一笔事务数据,除 此之外,Redis和MongoDB这样的NoSQL数据库也常用于数据的采集。
在大数据的采集过程中,其主要特点和挑战是并发数高,因为同时有可能会有成千上万的用户 来进行访问和操作,比如火车票售票网站和淘宝,它们并发的访问量在峰值时达到上百万,所以需要在采集端部署大量数据库才能支撑。并且如何在这些数据库之间 进行负载均衡和分片的确是需要深入的思考和设计。
虽然采集端本身会有很多数据库,但是如果要对这些海量数据进行有效的分析,还是应该将这 些来自前端的数据导入到一个集中的大型分布式数据库,或者分布式存储集群,并且可以在导入基础上做一些简单的清洗和预处理工作。也有一些用户会在导入时使 用来自Twitter的Storm来对数据进行流式计算,来满足部分业务的实时计算需求。
导入与预处理过程的特点和挑战主要是导入的数据量大,每秒钟的导入量经常会达到百兆,甚至千兆级别。









