正文
ASIC 专用芯片在吞吐量、延迟和功耗三方面都无可指摘,但微软并没有采用,出于两个原因:
1.数据中心的计算任务是灵活多变的,而 ASIC 研发成本高、周期长。好不容易大规模部署了一批某种神经网络的加速卡,结果另一种神经网络更火了,钱就白费了。FPGA 只需要几百毫秒就可以更新逻辑功能。
FPGA 的灵活性可以保护投资
,事实上,微软现在的 FPGA 玩法与最初的设想大不相同。
2.数据中心是租给不同的租户使用的,如果有的机器上有神经网络加速卡,有的机器上有 Bing 搜索加速卡,有的机器上有网络虚拟化加速卡,任务的调度和服务器的运维会很麻烦。
使用 FPGA 可以保持数据中心的同构性
。
接下来看通信密集型任务。相比计算密集型任务,通信密集型任务对每个输入数据的处理不甚复杂,基本上简单算算就输出了,这时通信往往会成为瓶颈。对称加密、防火墙、网络虚拟化都是通信密集型的例子。
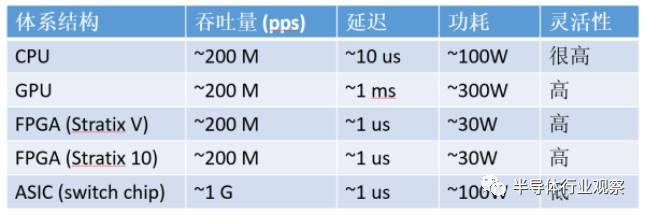
通信密集型任务,CPU、GPU、FPGA、ASIC 的数量级比较(以 64 字节网络数据包处理为例)
对通信密集型任务,FPGA 相比 CPU、GPU 的优势就更大了
。从吞吐量上讲,FPGA 上的收发器可以直接接上 40 Gbps 甚至 100 Gbps 的网线,以线速处理任意大小的数据包;而 CPU 需要从网卡把数据包收上来才能处理,
很多网卡是不能线速处理 64 字节的小数据包的
。尽管可以通过插多块网卡来达到高性能,但 CPU 和主板支持的 PCIe 插槽数量往往有限,而且网卡、交换机本身也价格不菲。
从延迟上讲,网卡把数据包收到 CPU,CPU 再发给网卡,即使使用 DPDK 这样高性能的数据包处理框架,延迟也有 4~5 微秒。更严重的问题是,
通用 CPU 的延迟不够稳定
。例如当负载较高时,转发延迟可能升到几十微秒甚至更高(如下图所示);现代操作系统中的时钟中断和任务调度也增加了延迟的不确定性。
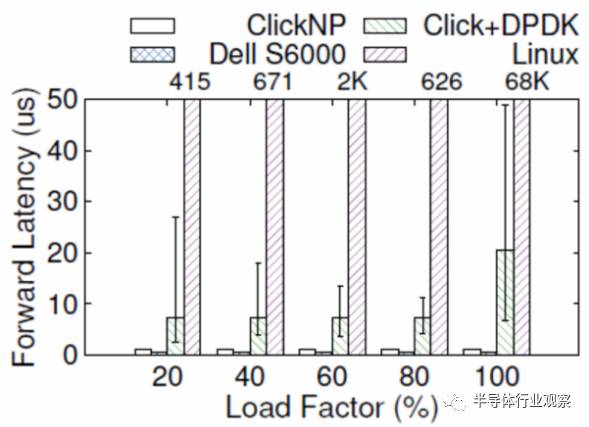
ClickNP(FPGA)与 Dell S6000 交换机(商用交换机芯片)、Click+DPDK(CPU)和 Linux(CPU)的转发延迟比较,error bar 表示 5% 和 95%。
虽然 GPU 也可以高性能处理数据包,但 GPU 是没有网口的,意味着需要首先把数据包由网卡收上来,再让 GPU 去做处理。这样吞吐量受到 CPU 和/或网卡的限制。GPU 本身的延迟就更不必说了。
那么为什么不把这些网络功能做进网卡,或者使用可编程交换机呢?
ASIC 的灵活性仍然是硬伤
。尽管目前有越来越强大的可编程交换机芯片,比如支持 P4 语言的 Tofino,ASIC 仍然不能做复杂的有状态处理,比如某种自定义的加密算法。
综上,
在数据中心里 FPGA 的主要优势是稳定又极低的延迟,适用于流式的计算密集型任务和通信密集型任务
。
二、微软部署 FPGA 的实践
2016 年 9 月,《连线》(Wired)杂志发表了一篇《微软把未来押注在 FPGA 上》的报道 [3],讲述了 Catapult 项目的前世今生。紧接着,Catapult 项目的老大 Doug Burger 在 Ignite 2016 大会上与微软 CEO Satya Nadella 一起做了 FPGA 加速机器翻译的演示。
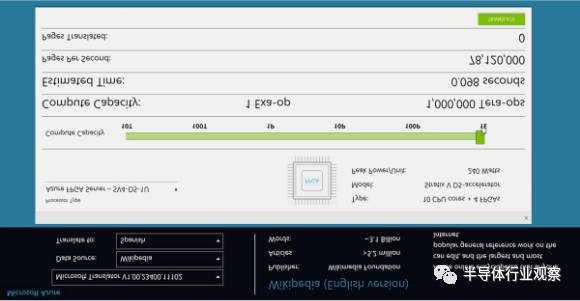
Ignite 2016 上的演示:每秒 1 Exa-op (10^18) 的机器翻译运算能力
这里就给大家八一八这个每秒 1 Exa-op 的数字是怎么算出来的。每块生产环境中部署的 Stratix V FPGA 有 1.8 T ops 的计算能力,每台服务器上插一块 FPGA。实际使用时,每 8 台服务器为一组,一台服务器作为 FPGA 的控制节点。控制节点的 CPU 也可以做机器翻译的计算,但是每个 CPU 核只能做 0.1 T ops,相比 FPGA 是聊胜于无。非控制节点上的 FPGA 通过网络从其他 FPGA 收发数据,不需要本地 CPU 处理数据平面。
截至演示时,微软 Azure 云有 46 万台服务器部署了 FPGA,Bing 有 1.5 万台,Exchange 服务有 9.5 万台,共计 57 万台。乘起来得到总的计算能力是 103 万 T ops,也就是 1.03 Exa-op,相当于 10 万块顶级 GPU 计算卡。一块 FPGA(加上板上内存和网络接口等)的功耗大约是 30 W,仅增加了整个服务器功耗的十分之一。
微软部署 FPGA 并不是一帆风顺的。对于把 FPGA 部署在哪里这个问题,大致经历了三个阶段:
1.
专用的 FPGA 集群,里面插满了 FPGA
2.
每台机器一块 FPGA,采用专用网络连接
3.
每台机器一块 FPGA,放在网卡和交换机之间,共享服务器网络

微软 FPGA 部署方式的三个阶段
第一个阶段是专用集群,里面插满了 FPGA 加速卡,就像是一个 FPGA 组成的超级计算机。下图是最早的 BFB 实验板,一块 PCIe 卡上放了 6 块 FPGA,每台 1U 服务器上又插了 4 块 PCIe 卡。

最早的 BFB 实验板,上面放了 6 块 FPGA
可以注意到该公司的名字。在半导体行业,只要批量足够大,芯片的价格都将趋向于沙子的价格。据传闻,正是由于该公司不肯给「沙子的价格」 ,才选择了另一家公司。当然现在数据中心领域用两家公司 FPGA 的都有。
只要规模足够大,对 FPGA 价格过高的担心将是不必要的










