正文
这是P范数的表达式。其实P范数具有一种泛化的表达式,是一种通用的方式,可以包含L1、L2,还有无穷范式,这些都是由P的取值决定的,可以等于1、等于2、等于无穷。

行列式的计算方法比较复杂,公式我就不列了。直接给出直观理解:衡量一个向量在经过矩阵运算后会变成什么样子,即线性空间上进行了某种放缩,可能是放大或者缩小,缩放的倍率就是行列式值;行列式的符号(正或负),代表着矩阵变换之后坐标系的变化。
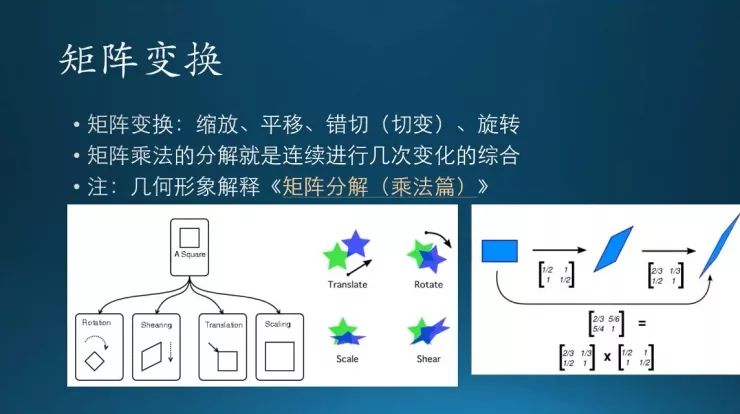
矩阵变换里面有这么几种,平移、缩放等等。这个后面再说,免得重复。

矩阵分解:
(1)特征值分解,是我们常规见到的。有一个定义,比如我们定义一个矩阵A,乘以一个向量得到的等于另外一个数字乘以同一个向量,Av=λv。满足这个表达式,就叫做矩阵的特征值分解,这是矩阵分解典型的形式。这个v就是一个特征向量,而这个λ就是特征值,它们是一一对应的(出生入死的一对好基友)。符合表达式可能还有其他取值,每一个矩阵A会对应多组特征向量和特征值;矩阵A的所有特征向量和特征值都是一一对应的。
如果矩阵是一个方阵(不只M等于N,还需要保证这个矩阵里面每一行、每一列线性无关),可以做这样的特征分解,把A分成了一个正交矩阵乘对角阵乘同一个正交矩阵的逆。对角阵是把每一个特征向量一个个排下来。
还有个概念叫正定,是对任意实数,满足xAxt>0,就叫正定;类似的还有半正定,大于等于0是半正定;负定就是小于零。
(2)奇异值分解,是矩阵特征分解的一种扩展,由于特征分解有个很强的约束——A必须是一个方阵。如果不是方阵怎么办呢,就没有办法了吗?有的,就是用SVD奇异值分解,这个在推荐系统用的比较多。
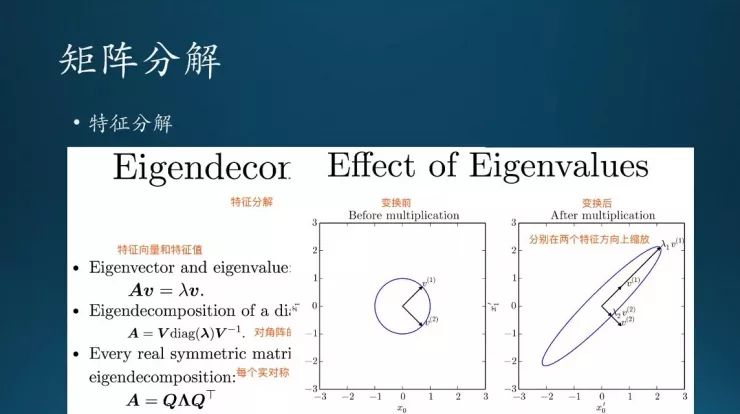
这是特征分解的示意图。从直观上理解,这个圆上面的两个向量V1、V2,经过矩阵变换之后在两个特征方向上进行缩放:在V1方向上面缩放λ1倍,变成了新的V1;V2在V2的方向做了λ2倍的缩放,变成新的V2。这两个特征,构成了完整的矩阵分解,也就是经过一个线性变换之后得到的效果——在特征向量方向上分别缩放特征值倍。

SVD分解就是一个扩展形式,表达方式就这样,不细说了。

向量和矩阵这两个组合起来就可以解决常见的线性方程组求解问题。
这里有几个概念,一个叫线性组合,就是一个矩阵,里面的一行或者一列,实际上就是多个向量,通过简单的加减还有数乘,组合出来一个新的向量,这叫线性组合。如果用基向量X1、X2执行加法和数乘操作,得到的是x3=k1*x1+k2*x2,一组向量组成的线性空间,即由X1、X2组合成的向量空间,就叫生成子空间。
如果对两个向量X和Y,可以按照α和1-α这两个数乘组合起来生成一个新的向量,这个叫线性表出,就是Z向量由X和Y进行线性表出,然后α和1-α都是一个数值,满足这个关系就叫线性相关。这就是说Z和X、Y是线性相关的,如果不满足,如果Z这个向量不能这样表出,就叫线性无关。
这是矩阵对应的一个线性方程组。这是一个矩阵,现在像右边这样把它展开,就是矩阵和线性方程组是对应的。这个挺常见的我不就不多说了。

矩阵方程组的求解是,把方程组每一个系数组成矩阵A,根据A这个矩阵本身的特性就可以直接判断这个方程组有没有解、有多少解。还有无解的情况。

这是矩阵方程组的一些求解,比较常规的,像AX=b这个线性方程组一般怎么解呢?常规方法:两边直接乘A的逆矩阵。它有个前提:A的逆必须存在,也就是说A里每一行、每一列不能线性相关。这种方法一般用于演示,比如算一些小型的矩阵,实际情况下,A的规模会非常大,按照这种方法算,代价非常大。

再看下什么矩阵不可逆。一个矩阵M×N,按照M、N的大小可以做这样的分类:如果行大于列,通常叫做长矩阵,反之叫宽矩阵;行大于列,而且线性无关,就是无解的情形。宽矩阵有无数个解,其中,每一列代表一个因变量,每一行代表一个方程式。

伪逆是逆的一种扩展,逆必须要求A这个矩阵式满秩,就是没有线性表出的部分。如果不满足,那么就得用伪逆来计算,这只是一种近似方法。SVD这种方法比较厉害,因为支持伪逆操作。
应用案例里,书里面只提到一个PCA,线性降维,也没有详细的展开。其实书里很多章节都提到了PCA,所以我也给大家普及一下基本概念。

这个是PCA在图像上面的应用。这张图非常经典,凡是学过数字图像处理的都知道她——Lenna(提示:别去搜lena的全身图,~~~~(>_
The Lenna Story
」)。原图像经过主成分分析降维之后就变成右边的图,可以看到大部分信息都都还在,只是有些模糊。这个过程叫降维,术语是图像压缩。
看一下PCA的基本过程。PCA的思想是,原来一个矩阵有很多列,这些列里可能存在一些线性关系,如何把它降成更小的维度,比如说两三维,而且降维之后信息又能够得到很大程度的保留。怎么定义这个程度呢?一般是累计贡献率大概85%以上,这些主成份才有保留意义。这个累计贡献率是通过方差来体现的,样本分布带有一定的噪音或者随机分布,如果是在均值的左和右两个方向进行偏移的话,不会影响方差。方差等效于信息量。

这张图解释主成分分析的过程,用的是特征值分解,一个X的转置乘以X,然后对它做各种复杂的变换,大家看看就行了,想了解细节的话自己去找资料,具体过程一时半会儿讲不清楚。PCA最后有什么效果呢?看中间的坐标系给出示意图,原来的矩阵取了X1和X2两个维度,把样本点打出来能看到近似椭圆分布,而PCA的效果就是得到一组新的坐标系,分别在长轴和短轴方向,互相正交,一个方向对应一个主成分。实际上,数据特征多于两维,图里只是为了方便观察,这样就完成了一个降维的过程。
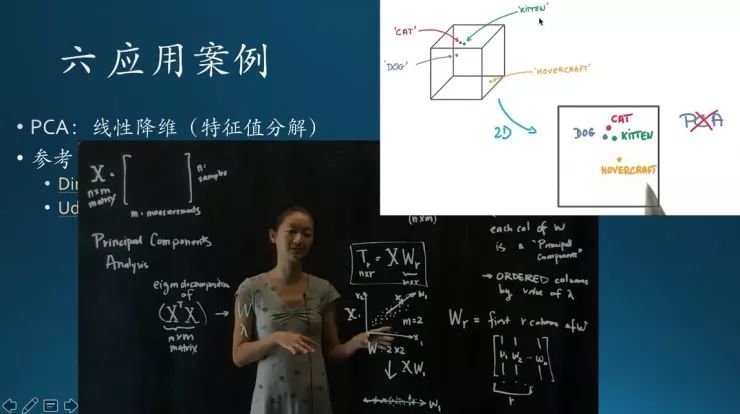
右上是一个示例,有一些动物样本,狗、小猫,还有个气垫船(非动物)。在特征空间里面显示成这样,理论上,动物会靠得比较近,非动物会远离。如果用PCA来做,可能得到的结果是这个样子,动物跟非动物区分的不是很明显。所以,PCA实际上只能解决一些线性问题,非线性情况下,解决的效果不太好。
怎么办呢?用非线性降维方法。典型的方法比如说t-SNE(t分布-随机近邻嵌入),流形学方法。
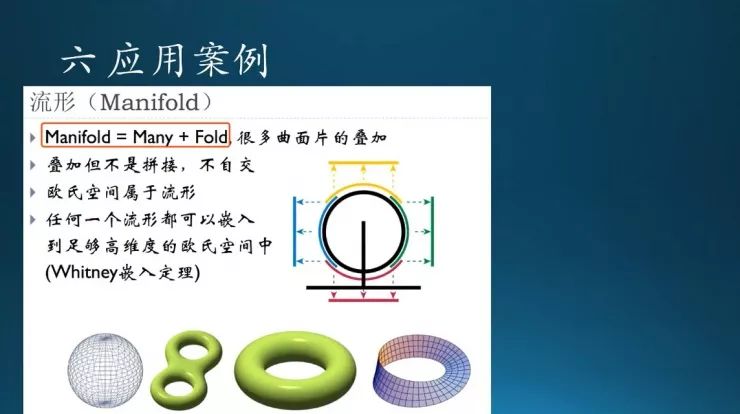
流形简单来说就是很多面片叠加形成的几何图形。基本假设是,同一个数据集中每个样本会近似服从一定的内在分布,比如说空间几何体里的圆形或球面,甚至正方形,都本身有一定内在结构。流形就是试图用非线性的方法找到内在结构,然后把它映射到低维的空间里面去。这个好像要讲深了,我先不做扩展(涉及拓扑几何)。后面好几个章节要提到流形,流形这个概念是需要了解的,后面自编码器章节还会提到。

这是一个复合、螺旋形的数据集,在空间里面显示出来是这个样子,用线性方法是不可能分开的。流形怎么办呢?近似于找到一种非线性的方法,假设这两个小人,把它拉伸,拉开之后,不同的类别就能够分开了。流行学习就相当于这两个小人把二维流形拉平了,从非线性的变成线性的。

这个图说的是PCA,2006年之前这种方法是非常实用的,一旦提到降维首选是PCA。基本思想就是在数据集里面方差变化最大的方向和垂直的方向选了两个主成分,就是V1和V2这两个主成分,然后对数据集做些变换,它是线性的。









