正文
论文地址:http://dl.acm.org/citation.cfm?id=3021740
英特尔 Programmable Solutions Group 的 FPGA 架构师以及论文的联合作者之一 Randy Huang 博士说:
深度学习是人工智能之中一个最激奋人心的领域,其取得了人工智能领域的最大进展,并催生出了最多的应用。尽管人工智能和 DNN 研究者喜欢使用 GPU,但我们发现英特尔新一代 FPGA 架构与应用领域之间存在着一个完美的契合。我们关注着即将来临的 FPGA 技术进步,DNN 算法的快速进展,并考虑着未来的高性能 FPGA 在新一代 DNN 算法的表现上能否胜过 GPU。通过研究我们发现在 DNN 研究中 FPGA 表现很好,并可用在人工智能、大数据或机器学习等需要分析大量数据的研究领域。当使用剪枝过的或紧密的数据类型 VS 全 32 位浮点数(FP32)时,被测试的英特尔 Stratix 10 的表现胜过了 GPU。除了性能之外,FPGA 同样很强大,因为其适应性强,并且可通过复用一个现存的芯片而容易地实现变化——一块芯片就可帮助一个团队在 6 个月内把一个想法做成原型,而打造一个 ASIC 则需要 18 个月。
测试中使用的神经网络机器学习
神经网络可以被表示为由加权边(weighted edges)互连起来的神经元图。每个神经元(neuron)和边(edge)都分别与一个激活值与权重相关联。神经网络结构由多层神经元组成。如下图 1 所示:
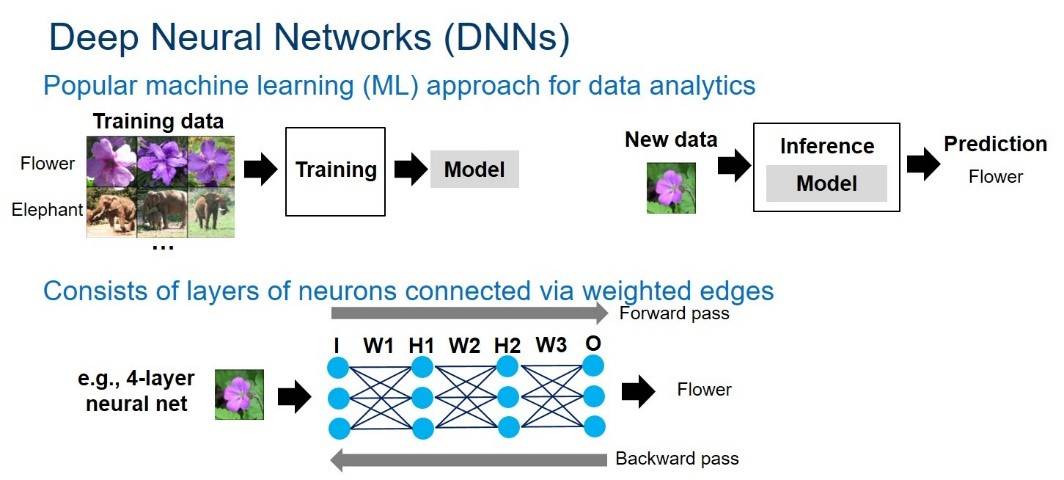
图 1:深度神经网络概观。该图由 Intel 提供。
神经网络的计算在网络中逐层传递。对于一个给定的层,每个神经元的值由前一层神经元的值与边权重(edge weight)累加相乘计算而成。计算在很大程度上基于乘积-累加操作。DNN 计算由正向与反向通过组成。正向通过在输入层获取一个样本,然后遍历隐藏层,在输出层产生一个预测。对于推理而言,只需要正向通过就能获得一个给定样本的预测结果。对训练而言,从正向通过中得到的错误预测接下来会在反向通过过程中被返回,以此来更新网络的权重——这被称为「反向传播算法(back-propagation algorithm)」。训练会反复进行正向与反向通过操作,从而以此来修正神经网络的权重直到模型可以产生理想精度的结果。
使 FPGA 成为可选项的改变
硬件:尽管和高端 GPU 相比,FPGA 的能量效率(性能/功率)会更好,但是大多数人不知道它们还可以提供顶级的浮点运算性能(floating-point performance)。FPGA 技术正在快速发展。即将上市的 Intel Stratix 10 FPGA 能提供超过 5000 个硬浮点单元(DSP),超过 28MB 的片上内存(M20K),同时整合了高带宽内存(最高可达 4x250GB/s/stack 或 1TB/s),以及由新的 HyperFlex 技术的改善了的频率。英特尔 FPGA 能提供全面的从软件生态系统——从低级硬件描述语言到 OpenCL、C 和 C++的高级软件开发环境。使用 MKL-DNN 库,英特尔将进一步将 FPGA 与英特尔机器学习生态系统和诸如 Caffe 这样的传统架构结合起来。Intel Stratix 10 基于英特尔的 14 纳米技术开发,拥有 FP32 吞吐量上 9.2TFLOP/s 的峰值速度。相比之下,最新的 Titan X Pascal GPU 提供 FP32 吞吐量 11TLOP/s 的速度。
新兴的 DNN 算法:更深的网络可提升精确度,但需要极大地增加参数数量,模型也随之变大;而这一切将对计算力、内存带宽和存储提出更苛刻的要求。如此,人们开始转向更高效的 DNN。采用比 32 位更少的紧密低精度数据类型成为了一个新兴趋势;由 DNN 软件框架(即 TensorFlow)支持的 16 位和 8 位的数据类型正在成为新标准。此外,研究者已经在极低精度 2 位三进制与 1 位二进制 DNN(其值分别地被限制为 (0,+1,-1) 或 (+1,-1))中取得了连续的精度提升。最近 Nurvitadhi 博士合写的一篇论文首次表明,三进制 DNN 能在众所周知的 ImageNet 数据集中取得当前最高的(即,ResNet)精确度。稀疏性(零的存在)是另一个新兴趋势,其可以通过剪枝、ReLU 和 ternarization 等技术被引入到 DNN 的神经元和权重之中,并产生带有 50% 至 90% 零的 DNN。因为没必要在这样的零值上计算,所以如果执行稀疏 DNN 的硬件可以有效地跳过零值计算,那么性能势必提升。





