正文
看到这里,很容易能统一我对于流计算处理的观点,即流计算是更宽泛。 它和是不是块和非块并没有关系,仅仅只是一个底层数据里包含了时间定义的处理机制,并不要求对于处理的数据需要有一个静态的快照。这意味着流计算处理系统以一个用户控制的频率来产出结果,而不是一直等到数据全部到达。从这个角度看,流计算是批次计算的一个更泛化的操作。考虑到现在实时数据的的普及,这应该是一个更重要的泛化。
为什么这种传统的对于流计算处理的观点成为一个先进的应用。我认为最大的原因是因为缺乏实时数据收集的方法,从而让持续处理成为某种理论上的想法。
我确实认为缺乏实时数据收集的方法是商用流计算处理系统的梦魇。它们的客户依然是在做面向文件的日复一日的ETL和数据集成。构建流计算处理系统的公司一般专注于提供计算引擎来处理实时数据,但却发现现实中很少有客户有实时数据流。事实上在我在领英的早期时光,有个公司试图卖给我们一套非常酷的流计算处理系统,但因为当时我们所有的数据都是按小时收集的文件,所以我们所能想到的就是把这些小时文件在每小时结束的时候喂给这个系统。这个公司的工程师发现这是一个非常常见的问题。唯一真实的例外就是金融界。在这个领域里流计算处理有一些成功的案例,而恰恰是因为这个领域里实时流数据才是主流,而如何处理这些实时数据流才是主要关注点。
即使是在健康的批处理生态系统里,实际上流计算处理作为基础架构类型的适用性也是很强的。它涵盖了实时处理/相应业务和离线批处理业务的基础架构上的鸿沟。对于现代的互联网企业,我认为大约25%的代码是关于这种鸿沟的。
现在发现日志(log)解决了流计算处理里的一些非常关键的技术问题。后面我会陆续介绍这些问题,但其中最大的问题它解决的就是它让数据成为了实时的多订阅者的数据导入机制。
对那些希望能更多了解日志和流计算处理间的关系人,我们提供了开源的Samza,一个专门为这些想法构建的实时流计算处理系统。在这个链接里面我们很详细地介绍了这些想法的应用。但这不是专门为了某个特定的流计算处理系统的,因为几乎所有的主要流计算处理系统都和Kafka有某种程度的集成,让Kafak来作为数据的日志来进行处理。
数据流图
▼
关于流计算处理的最有趣的方面就是它和一个流计算处理系统的内部机制没有任何关系,相反的是,相关的是他扩展了我们前面数据集成讨论里的数据源的观点。我们主要讨论了主要数据源和主要数据的日志化。即事件和数据都是直接由各种应用运行中生成的。流计算处理让我们可以也包含从其他数据源里计算出的数据源。 这些计算出来的数据源对消费者而言与用来计算其的其他数据源没什么区别(请参看图1-2)。
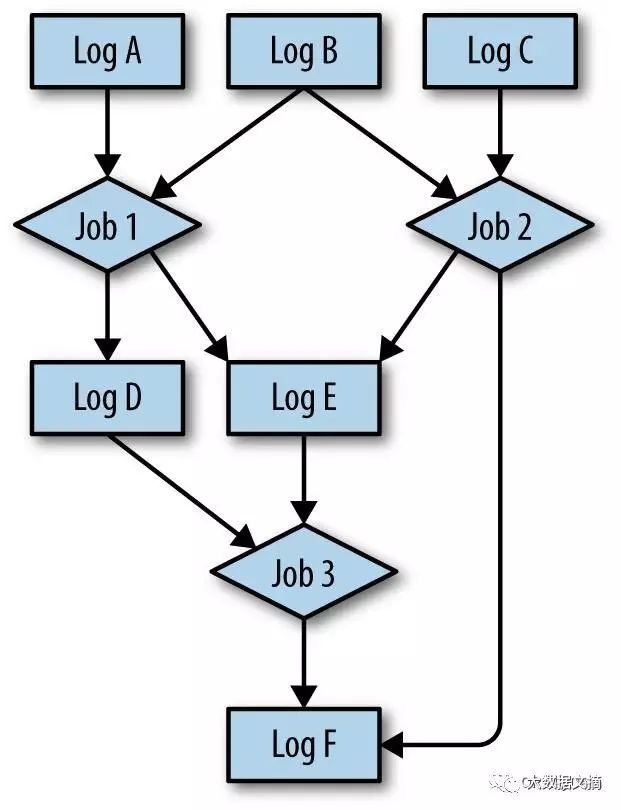
图1-2.来自多日志的多路流处理图
这些计算出来数据源可能会包含相当复杂和智力的成分在其处理过程里,因此也是极具价值的。例如,谷歌在这里描述了它是如何在一个流计算处理系统上重构它的网页爬取、处理和建索引的管道的过程。这可能是这个行星上最复杂、最大规模的数据处理系统之一了。
所以什么是流计算处理过程?对于我们的目的而言,一个流计算处理工作就是那些从日志中读取并输出到日志或其他系统的任务。那些作为输入和输出的日志把整个流程连接成了一个处理阶段的图。使用这种中心化日志的形式,你就能观察所有机构的数据的获取、转换和流动,其实就是一系列日志以及从他们中读出和写入他们的过程。
一个流计算处理过程并不必需要有一个时髦的框架。它可以是任何一个或多个读取和写入日志的过程。额外的基础架构和支持能够帮助管理和扩展这种近乎实时的处理过程程序,而这也就是流计算框架所做的。
日志和流计算处理
▼
为什么你在所有的流计算处理里需要日志?为什么不是让处理单元通过简单的TCP或者其他轻量级的消息协议来更直接的通信?有多个理由来支持这一(日志)模式。
首先,这种模式可以让每个数据集都能为多订阅者所用。每个流处理过程的输入对任何需要的处理器都可用;同时每个输出也都对任何需要的都可用。这一点不仅对生产数据流很好用,而且也在复杂的数据处理管道里调试和监控阶段很有帮助。能快速的进入一个输出流并检查它的有效性,同时计算一些监控的统计数据,或者仅仅只是看看数据长什么样,这些都使得开发变的非常有可追踪性。
其次,这样使用日志能确保每个数据消费者处理过程中顺序可以被保留。某些事件数据可能被按时间戳松散地排序了,但是不是每种事件数据都这样。考虑从来自数据库的一个更新流,我们可能有一系列的流处理任务来处理这些数据并准备为搜索索引来做索引。如果对同一个记录同时做两次更新,那么我们最后可能在索引的最终结果出错。
这样使用日志的最后一个可能也是最重要(可探讨)的原因是它提供了缓存和对每个处理过程的隔离。
如果一个处理器产生结果的速度比它后续的消费程序的处理能力快,我们可以有三种选择:
丢弃数据在某些场合可能没什么。但是基本都是不可接受的,也从来不被希望这样做。
暂停(上游)处理听起来似乎是一个可接受的选择。但实际中这会成为一个很大的问题。考虑到我们需要的不仅仅是对单一的应用流程建立模型,而是为整个机构建立全套的数据流模型。这就将不可避免的形成一个复杂的数据处理流网络,由不同的部门团队的不同的数据处理器来组成,并支持不同的SLA。在这样复杂的数据处理网络里,如果因为后续处理能力不足或者失败而导致上游的数据产生器被暂停,这都会级联地影响上游数据流程序,从而使得的很多处理器都被暂停。










