正文
,hjust=
1
, vjust=
1
)) + theme(legend.position=
"top"
) + geom_tile(aes(fill=value)) + scale_fill_gradient(low =
"white"
, high =
"red"
)
p
dev.off()
输出的结果是这个样子的
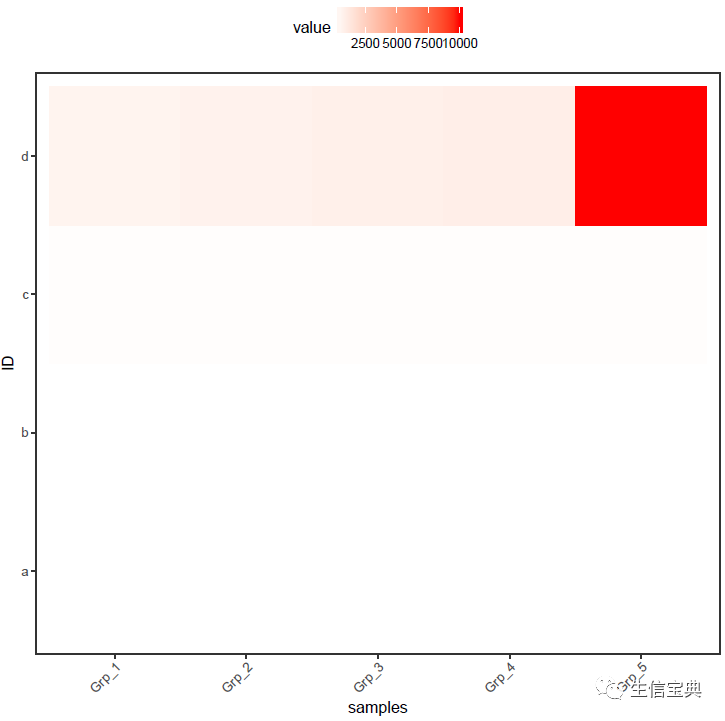
图中只有右上角可以看到红色,其他地方就没了颜色的差异。这通常不是我们想要的。为了更好的可视化效果,需要对数据做些预处理,主要有
对数转换
,
Z-score转换
,
抹去异常值
,
非线性颜色
等方式。
对数转换
为了方便描述,假设下面的数据是基因表达数据,4个基因 (a, b, c, d)和5个样品 (Grp_1, Grp_2, Grp_3, Grp_4),矩阵中的值代表基因表达FPKM值。
data 5,mean=5), rnorm(5,mean=20), rnorm(5, mean=100), c(600,700,800,900,10000))
data 5, byrow=T)
data rownames(data) 1:4]
colnames(data) "Grp", 1:5, sep="_")
data
Grp_1 Grp_2 Grp_3 Grp_4 Grp_5
a 6.61047 20.946720 100.133106 600.000000 5.267921
b 20.80792 99.865962 700.000000 3.737228 19.289715
c 100.06930 800.000000 6.252753 21.464081 98.607518
d 900.00000 3.362886 20.334078 101.117728 10000.000000
# 对数转换
# +1是为了防止对0取对数;是加1还是加个更小的值取决于数据的分布。
# 加的值一般认为是检测的低阈值,低于这个值的数字之间的差异可以忽略。
data_log 1)
data_log
Grp_1 Grp_2 Grp_3 Grp_4 Grp_5
a 2.927986 4.455933 6.660112 9.231221 2.647987
b 4.446780 6.656296 9.453271 2.244043 4.342677
c 6.659201 9.645658 2.858529 4.489548 6.638183
d 9.815383 2.125283 4.415088 6.674090 13.287857
data_log$ID = rownames(data_log)
data_log_m = melt(data_log, id.vars=c("ID"))
p "samples") + ylab(NULL) + theme_bw() + theme(panel.grid.major = element_blank()) + theme(legend.key=element_blank()) + theme(axis.text.x=element_text(angle=45,hjust=1, vjust=1)) + theme(legend.position="top") + geom_tile(aes(fill=value)) + scale_fill_gradient(low = "white", high = "red")
ggsave(p, filename="heatmap_log.pdf", width=8, height=12, units=c("cm"),colormodel="srgb")
对数转换后的数据,看起来就清晰的多了。而且对数转换后,数据还保留着之前的变化趋势,不只是基因在不同样品之间的表达可比 (同一行的不同列),不同基因在同一样品的值也可比 (同一列的不同行) (不同基因之间比较表达值存在理论上的问题,即便是按照长度标准化之后的FPKM也不代表基因之间是完全可比的)。










